进程间通信 (Inter-Process Communication, 简写为 IPC) 是两个进程之间进行信息交流的一种机制, 不仅仅会发生在同一主机的两个进程之间, 也可以发生在不同主机的两个进程之间, UNIX 的进程间通信方式有很多, 例如管道 (pipe), 信号量 (semaphore), 共享内存 (shared memory), 消息队列 (message queue) 以及套接字 (socket) 等, 本文梳理 UNIX 的进程间通信机制, 并给出部分场景的示例代码, 为了不陷入讨论冗长的 API 用法, 本文对部分 IPC 只给出相应的函数原型, 关于具体的用法读者可自行查阅 man page
20.1 UNIX 管道 (pipe)
管道 (pipe) 是使用非常频繁的进程间通信机制之一, 它最早出现于 Version 6 AT&T UNIX 上, 在 shell 中, 我们经常使用 | 将两个命令连接起来, 将前一个命令的输出作为后一个命令的输入, 这是管道使用最典型的例子, 常见的 UNIX 系统都有关于管道操作的 API, 最简单的使用管道的方式是通过 popen 调用和 pclose 调用 (该命令最早由 Version 7 AT&T UNIX 实现), popen 函数可以实现一个程序将另一个程序作为新进程来启动, 并且可以读取新进程的输出或向新进程输入数据, 这两个函数原型如下:
FILE *popen(const char *command, const char *open_mode);
int pclose(FILE *stream_to_close);
open_mode 参数将决定两个进程之间的数据流向 (我们将调用 popen 的进程称为调用进程, 将通过 popen 被调用的进程称为被调用进程), 当 open_mode 为 r 时, 调用进程可以通过 popen 函数返回的文件流指针利用诸如 fread 这样的函数来读取被调用进程的输出, 反过来, 当 open_mode 为 w 时, 调用进程可以使用 fwrite 函数向被调用进程写数据, 此时被调用进程可以通过标准输入流读取调用进程传递给它的数据, pclose 函数用来关闭调用进程和被调用进程之间建立的管道, 注意 pclose 函数只有在被调用进程退出以后才会返回, 若在被调用进程退出之前调用 pclose 函数, 则 pclose 函数将阻塞直到被调用进程退出
我们来给出一个具体的示例, ls 是 UNIX 内置的列出当前目录文件列表的命令, 我们可以写一个程序, 通过 popen 来调用 ls 程序并将 ls 进程的输出传递给我们写的程序, 这样实现了 ls 进程与我们使用的程序示例进程的进程间通信, 代码示例如下:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main() {
FILE *read_fp;
char buffer[BUFSIZ + 1];
int chars_read;
memset(buffer, '\0', sizeof(buffer));
read_fp = popen("ls -la", "r");
if (read_fp != NULL) {
chars_read = fread(buffer, sizeof(char), BUFSIZ, read_fp);
if (chars_read > 0) {
printf("Output was:-\n%s\n", buffer);
}
pclose(read_fp);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
编译 / 运行上面这段代码, 可以看到如下输出:
Output was:-
total 192
drwxr-xr-x 8 yunqiang staff 256 Feb 14 11:08 .
drwxr-xr-x 6 yunqiang staff 192 Feb 14 11:08 ..
-rw-r--r-- 1 yunqiang staff 22845 Feb 14 11:06 CMakeCache.txt
drwxr-xr-x 14 yunqiang staff 448 Feb 14 11:08 CMakeFiles
-rw-r--r-- 1 yunqiang staff 5502 Feb 14 11:06 Makefile
-rw-r--r-- 1 yunqiang staff 1406 Feb 14 11:06 cmake_install.cmake
-rwxr-xr-x 1 yunqiang staff 49920 Feb 14 11:08 linux_practice
-rw-r--r-- 1 yunqiang staff 5503 Feb 14 11:06 linux_practice.cbp
在内部实现上, popen 将调用 fork() 产生子进程, 然后从子进程中调用 /bin/sh -c 来执行参数 command 的命令, 因此对于每次 popen 调用, 不仅会启动被调用的程序, 还会启动 shell
关于 popen 的说明
再来看一个由调用进程向被调用进程通过管道传递数据的例子, 被调用程序为 grep, 它通过正则表达式匹配输入的字符串中的数字, 并将匹配结果打印到标准输出上, 调用进程将原始字符串通过管道传递给被调用进程, 代码示例如下:
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main() {
FILE *write_fp;
char buffer[BUFSIZ + 1];
memset(buffer, '\0', sizeof(buffer));
sprintf(buffer, "abc123b");
write_fp = popen("grep -E '\\d+' -o", "w");
if (write_fp != NULL) {
fwrite(buffer, sizeof(char), strlen(buffer), write_fp);
pclose(write_fp);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
编译 / 运行如上代码, 将会得到如下输出:
123
除了 popen 之外, UNIX 还有 pipe 调用, 它比 popen 更底层, 它的函数原型如下:
int pipe(int file_descriptor[2]);
其参数是一个文件描述符数组, 该数组只有两个元素, 向 file_descriptor[1] 中写入的数据可以从 file_descriptor[0] 中读取, 二者是 FIFO 的关系, 来看一个具体的代码示例
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main(){
int data_processed;
int file_pipes[2];
const char some_data[] = "123";
char buffer[BUFSIZ + 1];
memset(buffer, '\0', sizeof(buffer));
if (pipe(file_pipes) == 0) {
data_processed = write(file_pipes[1], some_data, strlen(some_data));
printf("Wrote %d bytes\n", data_processed);
data_processed = read(file_pipes[0], buffer, BUFSIZ);
printf("Read %d bytes: %s\n", data_processed, buffer);
exit(EXIT_SUCCESS);
}
exit(EXIT_FAILURE);
}
上面这段程序向 file_pipes[1] 中写入字符序列 "123", 然后从 file_pipes[0] 中读取, 编译 / 运行如上的程序, 将会得到如下的输出:
Wrote 3 bytes
Read 3 bytes: 123
pipe 调用最有用的场景是用在进程 fork() 之后, 父进程和子进程之间的进程间通信, 代码示例如下:
#include <unistd.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
int main() {
int data_processed;
int file_pipes[2];
const char some_data[] = "123";
char buffer[BUFSIZ + 1];
pid_t fork_result;
memset(buffer, '\0', sizeof(buffer));
if (pipe(file_pipes) == 0) {
fork_result = fork();
if (fork_result == -1) {
fprintf(stderr, "Fork failure");
exit(EXIT_FAILURE);
}
if (fork_result == 0) {
data_processed = read(file_pipes[0], buffer, BUFSIZ);
printf("Read %d bytes: %s\n", data_processed, buffer);
exit(EXIT_SUCCESS);
} else {
data_processed = write(file_pipes[1], some_data,
strlen(some_data));
printf("Wrote %d bytes\n", data_processed);
}
}
exit(EXIT_SUCCESS);
}
在上面的代码示例中, 在进行 fork() 调用后, 根据 fork() 的返回值来判断当前是子进程还是父进程, 当返回值为 0 时代表当前是子进程, 子进程读取 file_pipes[0], 而父进程向 file_pipes[1] 中写入数据, 从而实现父子进程之间的进程间通信
在上面我们所讨论的利用管道进行进程间通信的例子中, 通信的进程都是有关联的, 即都是在一个进程和该进程所创建的进程之间进行的通信, 如果是对于两个独立的进程利用管道进行进程间通信可以使用命名管道 (named pipe), 命名管道是一种特殊的文件, 可以在 shell 中使用命名管道做一个进程间通信的实验, 在使用命名管道通信之前首先创建命名管道, 可以使用如下的命令
mkfifo <pipe-name>
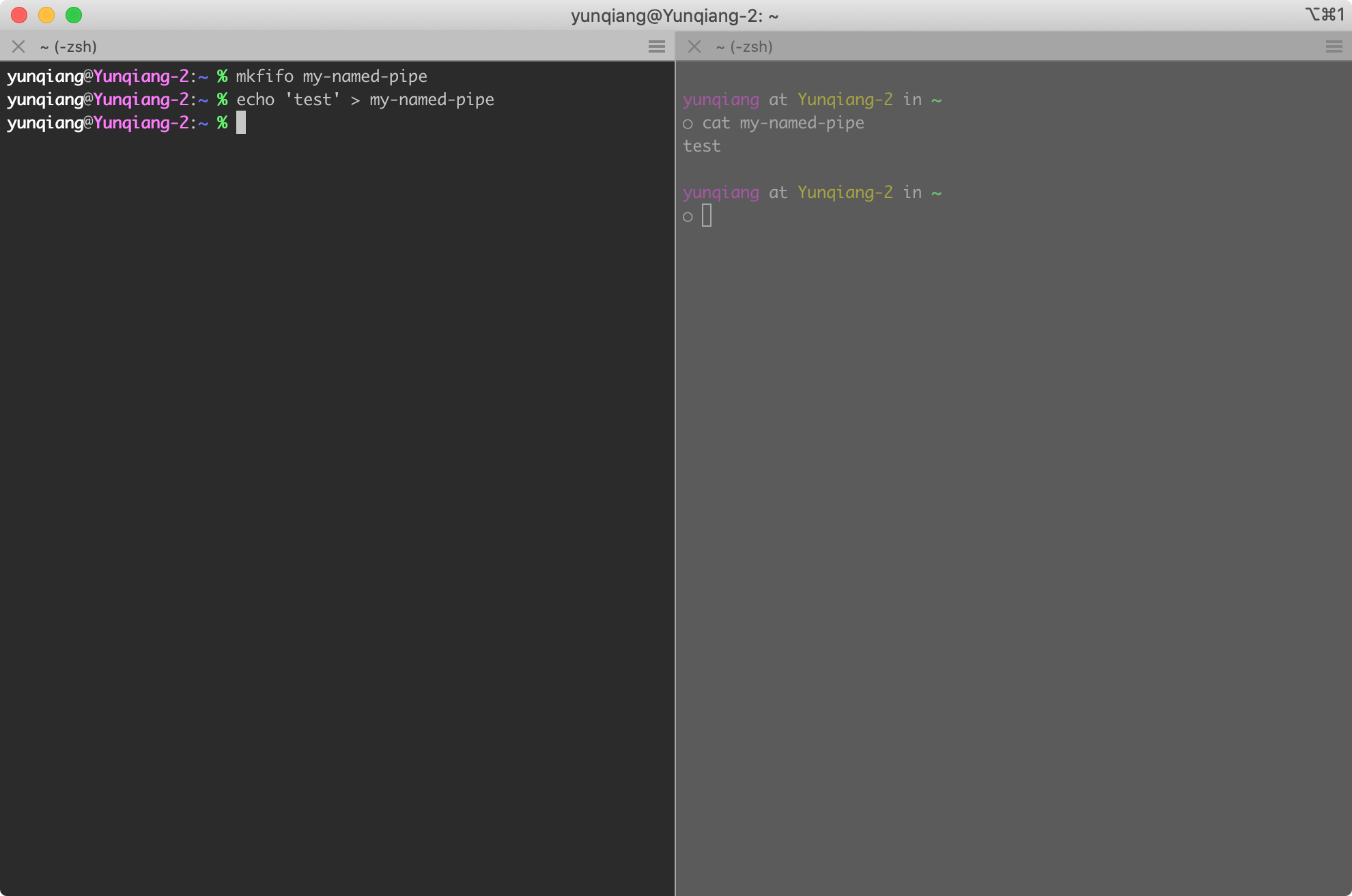
其中 <pipe-name> 是命名管道的名称, 例如我们创建一个名为 my-named-pipe 的命名管道, 然后同时打开两个 shell 进程, 左侧向 my-named-pipe 写入数据, 右侧通过 cat 命令读取数据, 如果在创建完命名管道之后首先运行 cat 命令, 则 cat 命令会处于阻塞状态, 因为当前管道中没有数据可读, 直到左侧的 shell 进程将数据写入命名管道后, 右侧的 cat 命令输出管道的数据并退出, 如下图所示:
此时, 创建了命名管道 my-named-pipe, 并在右侧的 shell 中执行 cat 输出管道数据, 因为还没有向管道写入数据, 所以 cat 命令处于阻塞状态:
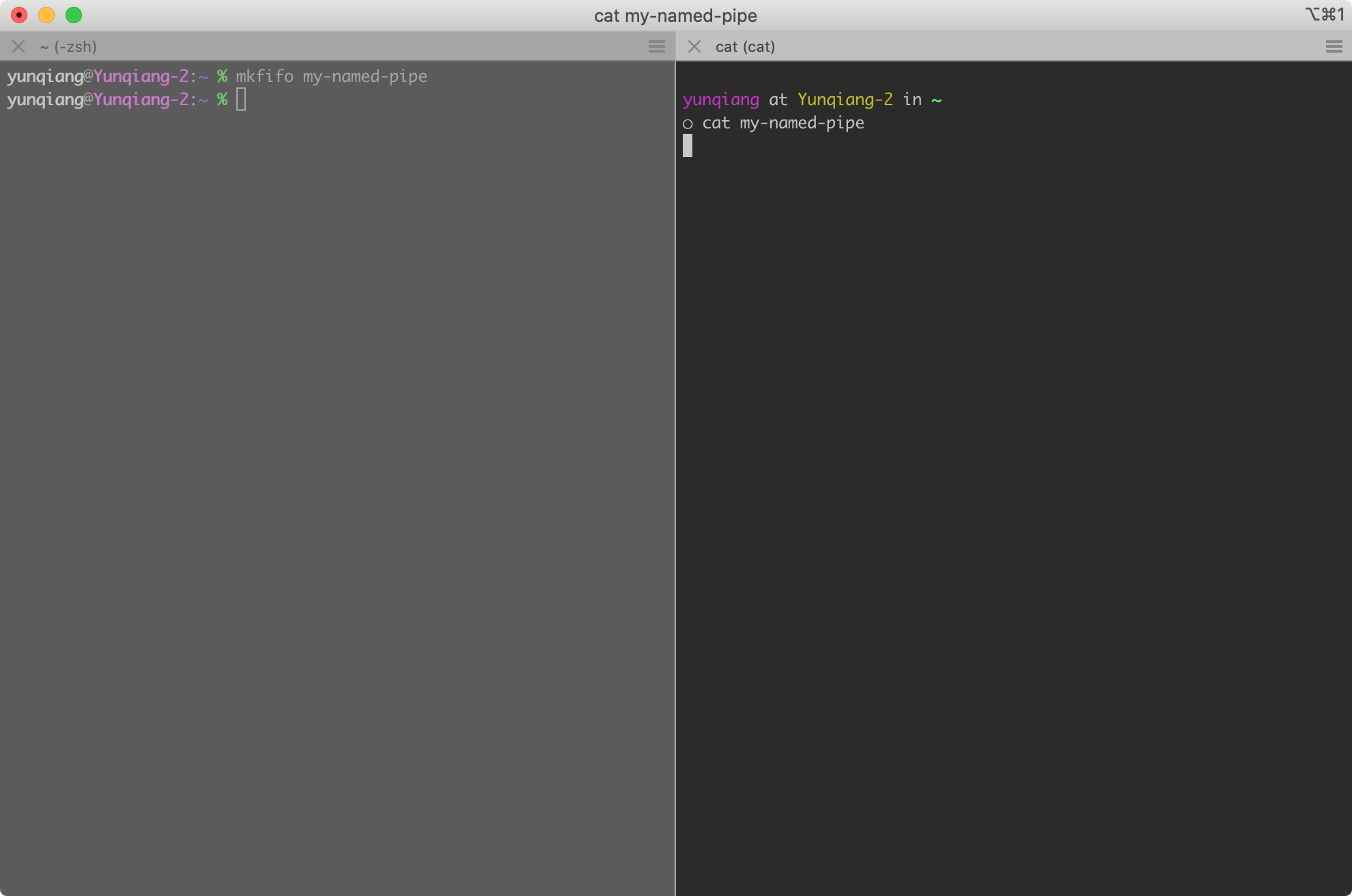
在左侧 shell 中向 my-named-pipe 写入数据, 右侧 cat 命令的阻塞状态接触, 输出管道数据并退出
命名管道也有相应的 UNIX API, 读者可以查阅 man page 获取相应的函数原型与用法, 此处不再赘述
20.2 UNIX 信号量 (semaphore)
信号量是由荷兰学者 Dijkstra 提出的, 它的原理比较简单, 但却能非常好地实现并发控制, 在并发执行的程序中, 如果它们都要访问同一个共享资源 (临界资源), 若此时不加以控制则可能会造成数据错误, 信号量可以非常方便地解决这个问题, 最简单的信号量可以是一个只能取 0 和 1 的变量, 信号量的操作有两个, 分别称之为 P 操作和 V 操作, 我们将信号量记为 s, 则 P(s) 调用的结果是若 s 的值大于 0 则减去 1, 否则挂起进程, V(s) 调用的结果是如果此时有因为执行 P(s) 操作而被挂起的进程, 则恢复该进程的运行, 否则将 s 的值加一, 每次程序要进入临界区时, 都首先调用 P(s), 如果调用成功, 说明当前没有其它进程或线程在访问临界区, 调用 P(s) 的同时也会将 s 的值减成 0, 从而阻止其它想要访问临界区的程序进入, 当操作完毕后, 调用 V(s) 释放对临界区的占用, 在 UNIX 中, 信号量操作有如下的函数:
int semctl(int sem_id, int sem_num, int command, ...);
int semget(key_t key, int num_sems, int sem_flags);
int semop(int sem_id, struct sembuf *sem_ops, size_t num_sem_ops);
关于它们的详细用法和参数的语义可以查阅 man page
20.3 UNIX 共享内存 (shared memory)
在同一操作系统上运行的多个进程之间, 它们是相互独立的, 每个进程都有自己的地址空间, 其它进程无法访问当前进程的内存区域, UNIX 的另一种进程间通信机制是使用共享内存, 共享内存是进程创建的特殊的地址空间, 不同进程可以将同一块内存地址连接到它们自己的内存空间中, 此时任何一个进程向共享内存区写入数据, 其它进程都可以读取到, 但共享内存本身没有提供同步机制, 共享内存区的读写需要程序员来维护, UNIX 关于共享内存有如下的 API:
// 创建共享内存
int shmget(key_t key, size_t size, int shmflg);
// 将创建的共享内存连接到进程自身的地址空间中
void *shmat(int shm_id, const void *shm_addr, int shmflg);
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);
// 将共享内存与当前进程的地址空间剥离开
int shmdt(const void *shm_addr);
关于它们的详细用法和参数的语义可以查阅 man page
20.4 UNIX 消息队列 (message queue)
消息队列和命名管道的通信机制比较类似, 但两者属于不同的 IPC 机制, 在命名管道中, 所有的数据都是严格 FIFO 的, 消息队列可以选择优先读取相应类型的消息, UNIX 关于消息队列有如下的 API:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
int msgget(key_t key, int msgflg);
int msgrcv(int msqid, void *msg_ptr, size_t msg_sz, long int msgtype, int msgflg);
int msgsnd(int msqid, const void *msg_ptr, size_t msg_sz, int msgflg);
关于它们的详细用法和参数的语义可以查阅 man page
20.5 UNIX 套接字 (Socket)
上面所讨论的 IPC 机制都是在同一主机上的不同进程之间的 IPC 方法, 对于位于不同操作系统上的进程可以通过 Socket 进行进程间通信, 这也是我们非常熟悉的 Socket 机制, 实际上 Socket 是通过建立诸如 TCP / UDP 等的传输层连接来进行数据传输的, 以可靠传输的 TCP 为例, 对于服务端来说, 首先调用 socket() 创建套接字, 然后调用 bind() 绑定套接字相关的配置 (如 IP / Port 等), 然后调用 listen() 监听 bind() 所绑定的端口, 最后调用 accept() 等待客户端的调用, 对于客户端来说, 首先调用 socket() 创建套接字, 然后调用 connect() 与服务端发起 TCP 握手, TCP 连接建立完成之后, 客户端调用 send() 发送数据, 服务端调用 recv() 接收并读取数据, 由于 TCP 是全双工的, 所以二者可以同时交替地调用 send() 和 recv(), 当通信完成之后, 客户端调用 close() 断开与服务端的 TCP 连接
Socket 不仅仅应用在两个不同主机之间的进程间通信, 对于同一主机上的两个进程也可以使用 Socket 来进行通信, 一方面可以使用 LoopBack 地址 127.0.0.1 来进行 Socket 通信, 但对于同一主机上的两个进程之间没有必要使用如此复杂的通信方式 (因为 TCP 需要做很多额外的控制, 如维护滑动窗口, 排序, 计算校验和等), 可以使用 UNIX Domain Socket 来实现, UNIX Domain Socket 不需要经过网络协议栈, 直接在两个进程之间进行数据传输, UNIX Domain Socket 与普通的 Socket 使用几乎相同的 API, 但需要将 Socket 类型设置为 AF_UNIX, 创建 UNIX Domain Socket 实际会在操作系统上创建一个 .sock 文件, 不同进程通过读写 .sock 文件来实现通信