最近我阅读了 Go MySQL 驱动代码, Go 语言的 database/sql 包定义一组 interface, 这组 interface 定义了 sql 操作的必要函数, 要编写相应数据库的 Go 语言驱动只需实现这个 Package 下的接口即可, 例如 mattn/go-sqlite3、go-sql-driver/mysql、lib/pq 等项目都是实现了 golang database/sql 的所有 interface 而编写的分别针对 sqlite、MySQL 和 PostgreSQL 的数据库驱动, 而 ORM 则是在这些驱动库的基础之上再实现了一层抽象, 我目前的工作主要面向 MySQL 数据库, 在看 Go MySQL 驱动代码的同时, 我阅读了 MySQL 的技术文档, 要自己实现 Go 的 MySQL 驱动, 则只需在逻辑层实现 MySQL 文档阐述的通信格式, 在语言层实现 Go database/sql Package 定义的 interface 即可, 本文不讨论语言层, 主要阐述 MySQL Client/Server 的通信协议, 了解了整个通信协议之后, 无论是针对什么编程语言, 哪怕是自己开发的新编程语言, 也都可以自行实现一个 MySQL 驱动, 基于 MySQL 驱动可以在上层做更多自定义的事情, 例如实现 MySQL 数据到 Redis、ElasticSearch、MongoDB 等的数据同步、开发 MySQL Proxy 等
5.1 协议数据类型
协议数据类型是与语言无关的数据类型, 可以理解为 wire type, 类似于在 Protobuf 编码原理 [Blog 1] 中所提到的 Varint、64-bit、Length-delimited 等类型, 它们是网络字节流中的数据类型, 在 MySQL 协议中数据类型只有两大类, 分别是整数(Integers) 和字符串(Strings), 这两种数据类型又会分为多个更小的数据类型, 对于整数类型, 可以进一步分为定长整数(Fixed-Length Integer) 和长度编码型整数(Length-Encoded Integer), 对于定长整数, 顾名思义, 其长度是固定的, 定长整数有 int<1>、int<2>、int<3>、int<4>、int<6>、int<8> 共 6 种, 定长整数都是以小端字节序存放的, 即最低有效位在前, 举例来说, 对于 int<4> 的数字 2, 其字节概况为 10 00 00 00; 而长度编码型整数, 它所占用的字节数不是固定的, 取决于值的大小, 记为 int<lenenc>, 这是一种变长编码方式, 长度编码型整数占用的字节数有 1、3、4、9 字节共 4 种情况, 数字越小, 占用的字节数越少, 当数字小于 0xfb 时, 编码后其占用一个字节, 当数字大于等于 0xfb 并且小于等于 0x7ffff 时, 其编码后将占用 3 个字节(固定的 0xfc + 2 个字节数值位), 当数字大于等于 0x10000 且小于等于 0x7fffff 时, 其编码后将占用 4 个字节(固定的 0xfd + 3 字节的数值位), 当数字大于等于 0x1000000 且小于等于 0x7ffffffff 时, 其编码后将占用 9 个字节(固定的 0xfe + 8 字节的数值位), 根据这样的编码规则, 反过来我们也能得到长度编码型整数的解码规则, 识别数据的第一个字节便可以知道其后所跟随的数值位的字节数, 进而可以获得数值本身, 也就是说长度编码型整数实际上是用开头的一字节来指示其后所跟的数据的字节长度, 而其后的数值字节仍然是以小端字节序存储, 这里实际上有点类似于 Redis 的 ziplist 结构中的结点, 在 Redis ziplist 结构中, 其结点的第一个元素 previous_entry_length 也是采用类似的结构来表示前一个结点的长度, 若前一结点的长度小于 254 个字节, 则 previous_entry_length 的本身就是前一结点的长度, 若前一结点的长度大于等于 254 个字节, 则 previous_entry_length 本身占用 5 个字节的长度, 其第一字节的值固定为 0xfe, 而后所跟的 4 个字节指示了其前一个结点的长度
字符串类型(Strings) 是字节序列构成的数据类型, 它可以细分为固定长度的字符串 string<fix>、空终结字符串 string<NUL>、变长字符串 string<var>、长度编码型字符串以及特殊的结尾字符串 string<EOF>, 所谓固定长度字符串, 顾名思义, 其长度是固定不变的, 而空终结字符串是以 0x00 字节指示字符串结尾, 长度编码型字符串是在开头指示了字符串的长度 , 然后其后跟 字节的固定长度字符串, 在长度编码型字符串中, 开头的字符串长度是使用长度编码型整数, 即 int<lenenc> 指示的, 而特殊的结尾字符串则用于在数据包的末尾, 因为数据包有自然的边界, 所以结尾处的字符串不需要特别设置一个结束标志位
所以总结下来, MySQL 协议中的所有数据类型有
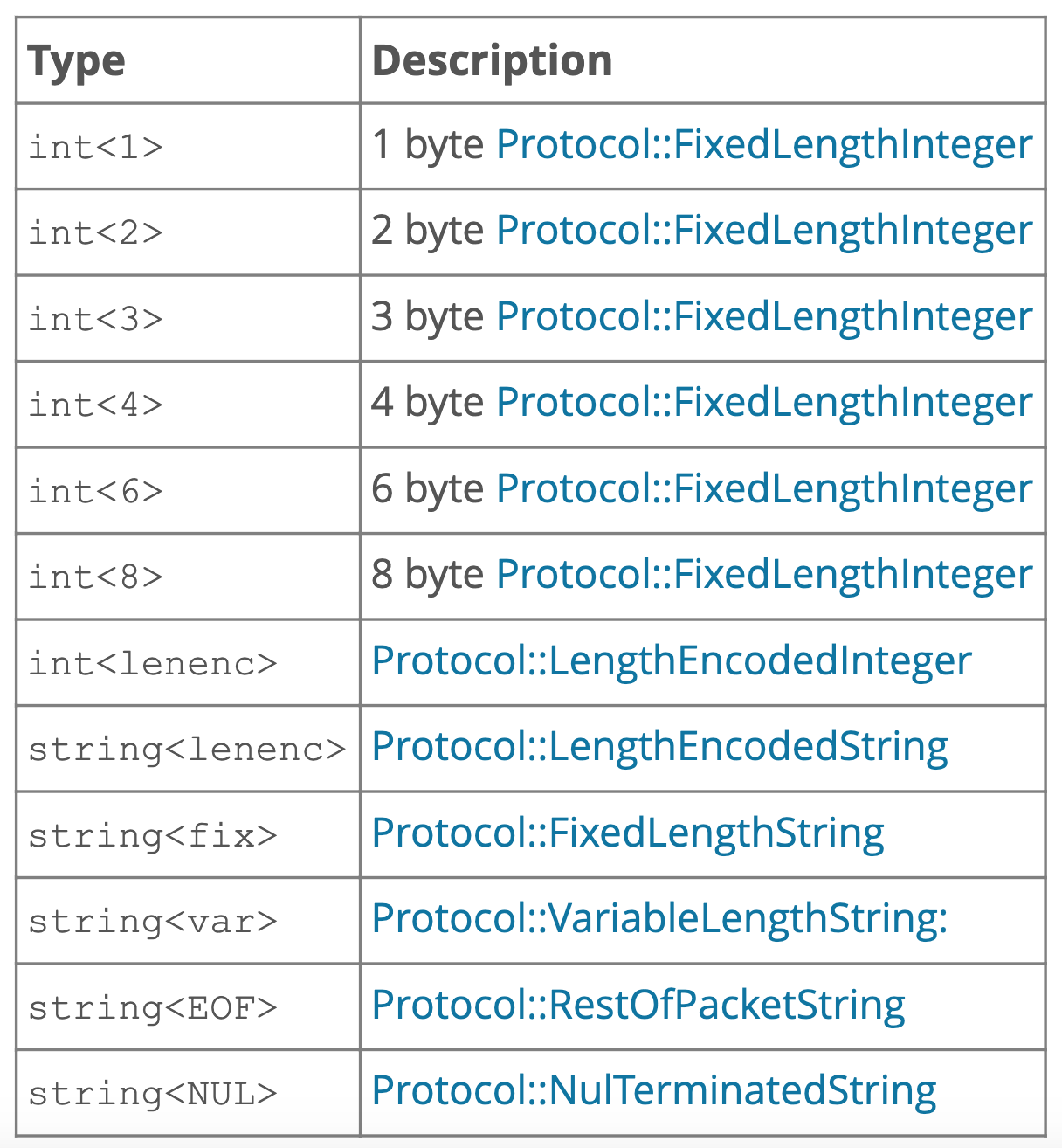
在 MySQL 交互的 Packet 中, 所有的数据都使用以上所定义的这些数据类型来表示
5.2 MySQL Packet 的一般格式
MySQL 的客户端和服务端交互是以数据包(Packet) 为单位进行的, 每个包的大小长度有限制, 最长为 个字节(即 16MB), 若包长度过大, 则客户端需要自行将包分片, 使得每段的长度在 MySQL 包的最大长度之下, MySQL Packet 由 Header 和 Body 组成, Header 包含两个字段: 包长度(payload_length)、序列号(sequence_id), Body 则是包的主体部分, 它的长度由 Header 中的 payload_length 字段指示, 包长度字段固定使用 int<3> 类型, 序列号固定使用 int<1> 类型, 当客户端和服务端开始交互时, 由客户端初始化 0 序列号, 之后每次交互, 数据发出方都基于前一个 sequence_id 增一, sequence_id 不是恒定唯一的, 当交互次数足够多后, 它会重新回到 0, MySQL 的 Packet 可以用如下所示的图来直观表示
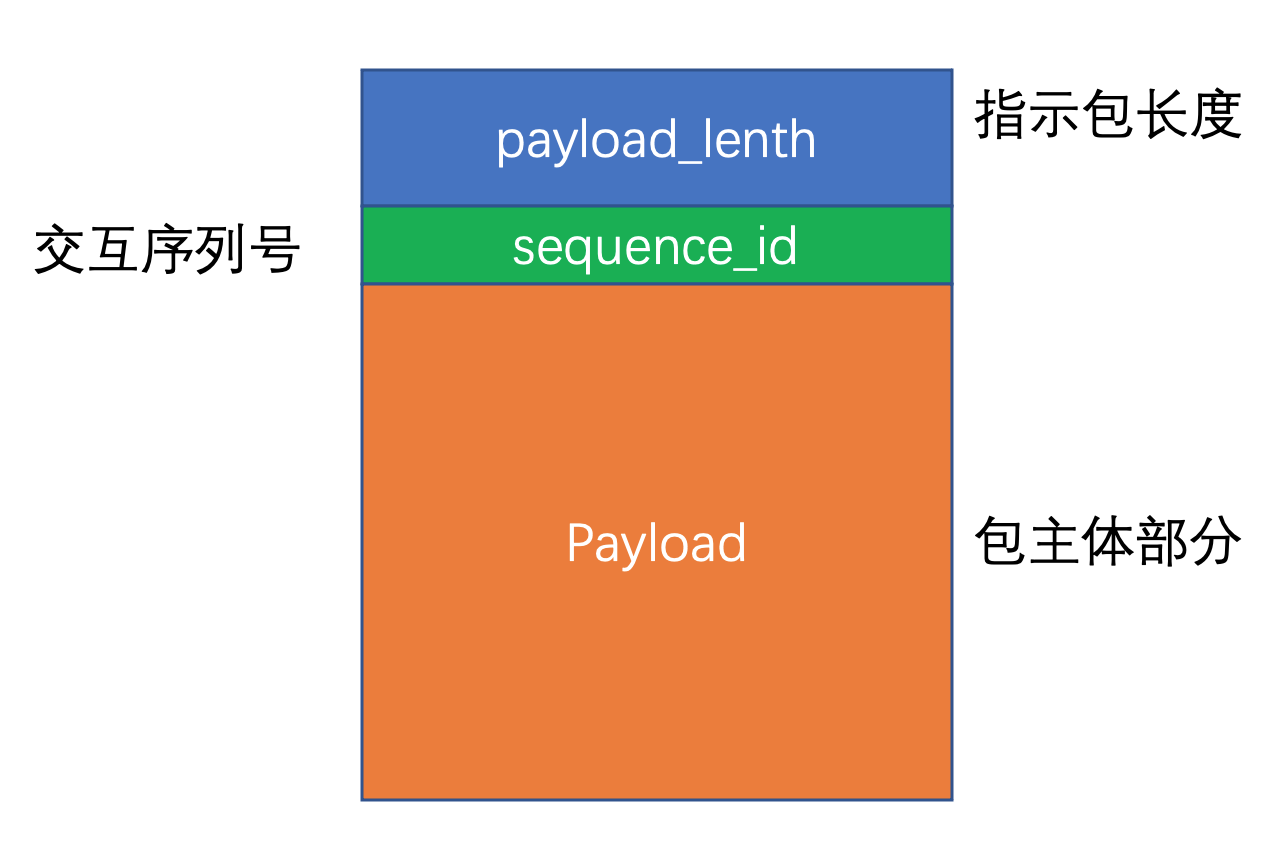
其中主体部分根据数据包类型的不同而不同, 当数据包长度超过 16MB 时, 发出方需要对 Packet 做分片, 当之后接收的数据包的 payload_length 小于 0xffffff 时意味着数据包的结束, 这里有一种特殊情况是, 若数据包的长度恰好是 0xffffff 的整数倍, 则最后一个分片的长度仍然是 0xffffff, 对于这种情况, 通信发出方需要再发送一个只包含 Header 的 Packet, 其 payload length 为 0x000000, 以便于通信接收方可以获知分片已经结束
5.3 通用响应包
对于大多数情况来说, 当客户端向服务端发出指令后, 服务端根据指令是否正确、操作是否成功向客户端返回成功或失败, 在 MySQL 中, 当指令执行正确、成功后, 服务端会向客户端返回 OK_Packet, 当发生错误时, 会向客户端返回 ERR_Packet, 我们先来讨论 OK_Packet 的数据结构, OK_Packet 的结构如图所示

这张图是对 OK_Packet 的 payload 的完整说明, 注意区分里面的 header, 这里我们讨论的是 Payload 的结构, 要注意与 Packet 的 Header 做区分, 在 MySQL 5.7.5 之后, Ok_Packet 与 EOF_Packet 共用一个结构, 都使用上图所示的 OK_Packet 结构, 其中 Payload 的 Header 字段可以协助指示当前该包是 OK_Packet 还是 EOF_Packet, 而 affected_rows 顾名思义是此次操作影响的行数, 对于查询操作其 affected_rows 恒等于 0, 而对于删除/更新等操作, 其 affected_rows 便为相应的影响的行数, last_insert_id 是最后一条插入数据表的数据的主键id, 从这往下的字段根据 capabilities 的不同而不同, 由于 MySQL 有诸多版本, 在 MySQL 的迭代过程中, 协议本身也在发展变化, 客户端和服务端的版本可能也有所不同, 为了最大程度地兼容客户端和服务端, 使得交互得以正常进行, MySQL 的客户端和服务端交互的时候会彼此相互交换能力信息, 接收方可以根据对方能提供的能力信息来解码对方发来的数据包, 详细能力信息的标志可以参考技术文档, 这些信息会在客户端和服务端初次握手的时候相互交换, 我们基于 MySQL 5.6+ 讨论协议格式, 其中 status_flags 指示了当前的服务端状态, 其具体定义可以参考技术手册
当客户端此次发出的指令有错误, 或服务端执行出错时, 服务端会向客户端返回 ERR_Packets, ERR_Packets 的结构如图所示

ERR_Packets 完整描述了错误信息, 包括错误码, 错误信息等, 若我们在日常开发中经常遇到的诸如 1062 Duplicate Key、1052 Unknown column 等错误都是通过 ERR_Packets 返回的
5.4 Client/Server 的握手
客户端要想和服务端进行通信, 首要先做的第一步是与服务端建立连接, MySQL 连接的方式有多种, 比如 TCP/IPv4、TCP/IPv6、UNIX domain sockets 等, 我们以 TCP 连接为例来讨论连接建立过程:
-
客户端与服务端建立 TCP 连接, 出于性能的考虑, 客户端和服务端之间一般建立 TCP 长连接, 这样可以避免每次客户端要与服务器通信都再进行一次连接建立操作, 客户端可以将建立好的 TCP 连接缓存在连接池中, 以便需要的时候可以直接拿来用
-
服务端向客户端返回 Initial HandShake Packet, 客户端解析包结构并返回 HandShake Response Packet, 数据包中携带能力交换信息, 要登录的用户等, 在这个阶段, 客户端也可以向服务端返回 SSL Connection Request Packet, 请求服务端开启 SSL 连接, 之后便是 SSL 的数据交换, 此过程完成以后, 客户端再向服务端返回 Handshake Response Packet
-
客户端在向服务端返回 HandShake Response Packet 时会告知服务端此次要登录的用户, 在 MySQL 中, 系统表 mysql.user 表的 plugin 字段标志了该用户所对应的鉴权方法, 比如 mysql_native_password 等, 服务端根据客户端返回的用户信息查询该 user 表的 plugin 字段获取该用户对应的鉴权方式, 并与客户端进行鉴权信息交换, 若鉴权成功, 则服务端最终向客户端发送 OK_Packets, 此时连接建立完成, 或发生比如鉴权未通过等其它情况时向客户端返回 ERR_Packets
整个过程的流程图如下所示
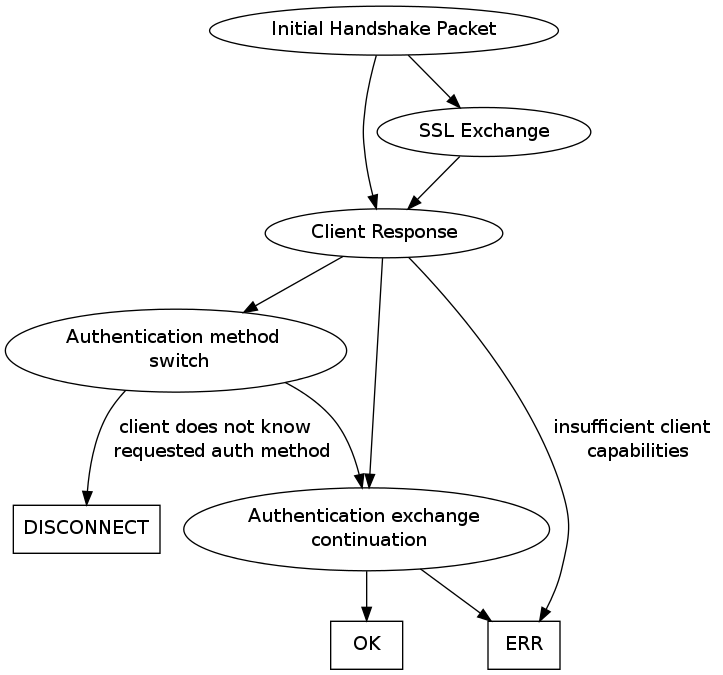
分析上面的连接建立过程我们可以看到, MySQL 服务端若要对客户端进行鉴权, 则必须等到客户端向服务端返回 HandShake Response Packets 后, 服务端从中取出此次要登录的用户, 然后去 mysql.user 表查询 plugin 字段获得该用户的鉴权模式, 然后再向服务端请求鉴权信息, 这实际上多了冗余的交互, 对于这一点, 在 Initial HandShake Packets 中, 服务端可以直接向客户端标识一个默认使用的鉴权模式, 客户端采用该模式在 HandShake Response Packets 返回使用该鉴权模式加密的数据, 这样便减少了鉴权交互, 提升连接效率
当客户端使用的鉴权模式与服务端要求的鉴权模式不相同, 或者即便是服务端自行选择了一个默认的鉴权模式发给客户端, 客户端也采用了该模式, 但该模式与客户端要登录的 user 对应 mysql.user 表的 plugin 字段指示的鉴权模式不相同, 则鉴权都是失败, 此时服务端向客户端返回 Authentication Method Switch Request Packet, 其中包含了所应该使用的正确的鉴权模式, 客户端应根据该数据包要求的鉴权模式重新向服务端发起鉴权, 若客户端不支持该鉴权模式则应断开连接, 此次连接失败, 关于鉴权的更多信息可以参考文档, 从连接过程我们可以看到 MySQL 的 Client/Server 之间是一种半双工的通信方式
5.5 SQL Query 数据包解析
MySQL 的命令有很多, 受篇幅限制, 这里一一不展开讨论每一种命令对应的客户端/服务端交互格式, 作为一个关系型数据库, 其主要的面向上层的功能便是增删改查, 以查询操作为例, 当客户端和服务器完成握手、鉴权等操作后, 客户端便可以向服务端发送它需要操作的指令, 比如客户端想要查询某个表的数据, 在 MySQL 中, 客户端需要向服务端发送 COM_QUERY Packet, COM_QUERY 的 Payload 非常简单, 第一个字节为指令编号(Command id), 对于查询操作, 其指令编号为 0x03, 然后紧跟着的便是具体的查询语句, 例如 SELECT * FROM user WHERE id = 1, 如下图所示

服务端收到 COM_QUERY 数据包后, 便解析 SQL 执行相应的查询操作, 执行完毕后向客户端返回 COM_QUERY Response, COM_QUERY Response 不是一个基本的数据包类型, 根据 SQL 执行结果的不同, COM_QUERY Response 会有不同的形态, 对于基本的查询的操作, 服务端会返回多个数据包, 其中包括列模式包的个数(我们记为 N), N 个列数据包(每个列数据包详细描述了数据表一个字段的信息, 诸如字段名称、字段数据类型、字段长度等), 以及一个或多个的行数据包, 每一个行数据包都包含 N 个值, 更详细的 Packet 字段可以参看技术手册
在 MySQL 中, 对于一条 SQL 语句, 服务端收到客户端的请求后, 会对 SQL 做语法和语义解析, 执行一定的优化并确定执行计划, 然后执行 SQL, 将结果返回给客户端, 而在实际业务场景中, 客户端执行的 SQL 往往都比较类似, 只有参数的不同, 比如我们需要查询某个用户的信息, SQL 语句的形态往往都是 SELECT * FROM user WHERE user_id = ?, 如果针对每个 user_id 都从头到尾执行一遍语法/语义解析、SQL 优化、确定执行计划等环节, 实际上效率比较低下, 因为其中的大多数环节都是冗余的, 对于这样的场景, 可以使用 Prepared Statement, 即将 SQL 语句作为一个模板, 而其中的参数使用占位符替代, 当客户端传入实际的参数时, 服务端将该参数插入到模板中, 这样可以大大提高 SQL 的执行效率, 与之相对的, 也就是我们在上面所讨论的一次编译、一次运行的 SQL 被称为即时 SQL(Immediate Statement), 在 MySQL 协议中, 对于 Immediate Statement, 服务端返回的都是文本形式的数据, 即 ASCII 编码的数据, 而对于 Prepared Statement, MySQL 服务端的 Response 采用了更紧凑的 Binary Protocol Resultset Row 格式来描述结果行, 具体来说, 在即时 SQL 中, COM_QUERY Response 结构中, 对于结果行中的 NULL 字段值, 会使用 0xfb 来替代, 客户端解析 Response 的 ResultRow 结构时, 如果读到某个字段是 0xfb 便会获知在该结果行中, 对应于该字段的值是 NULL, 而普通的非空字段值都会以字符串的形式返回给客户端, 在 Prepared Statement 中, MySQL 使用 bitmap 来优化 NULL 值的表示, 当查询结果行中含有较多的 NULL 值时, 传输效率将会提高很多
MySQL Bitmap 的计算方式是这样的, 假设此次查询出的结果对应 N 列, 则 Bitmap 的空间大小为 (N + 7 + Offset) / 8, 对于 Binary Protocol Resultset Row 结构, Offset 固定为 2, Bitmap 实际上就是一个字节数组, 数组的每个元素占一个字节的空间, 当结果行中某个字段的值为 NULL 时, 我们假设这个字段是第 M 个字段, 要将这个信息保存到 Bitmap 中, 首先便是要定位到其在 Bitmap 中的位置, 由于 Offset 的存在, 所以计算 Bitmap 位置的时候, 都需要加上 Offset, 因此它所需要保存到的字节数组的下标为 (M-1 + Offset) / 8, 而在字节内的偏移位为 (M-1 + Offset) % 8, 用一行伪代码表示便是
跟在 Bitmap 后的便是数据行具体的数值信息, 对于 Prepared Statement 查询结果的每一个数据行都构成一个单独的 packet, 其 Payload 的数据结构如下所示:
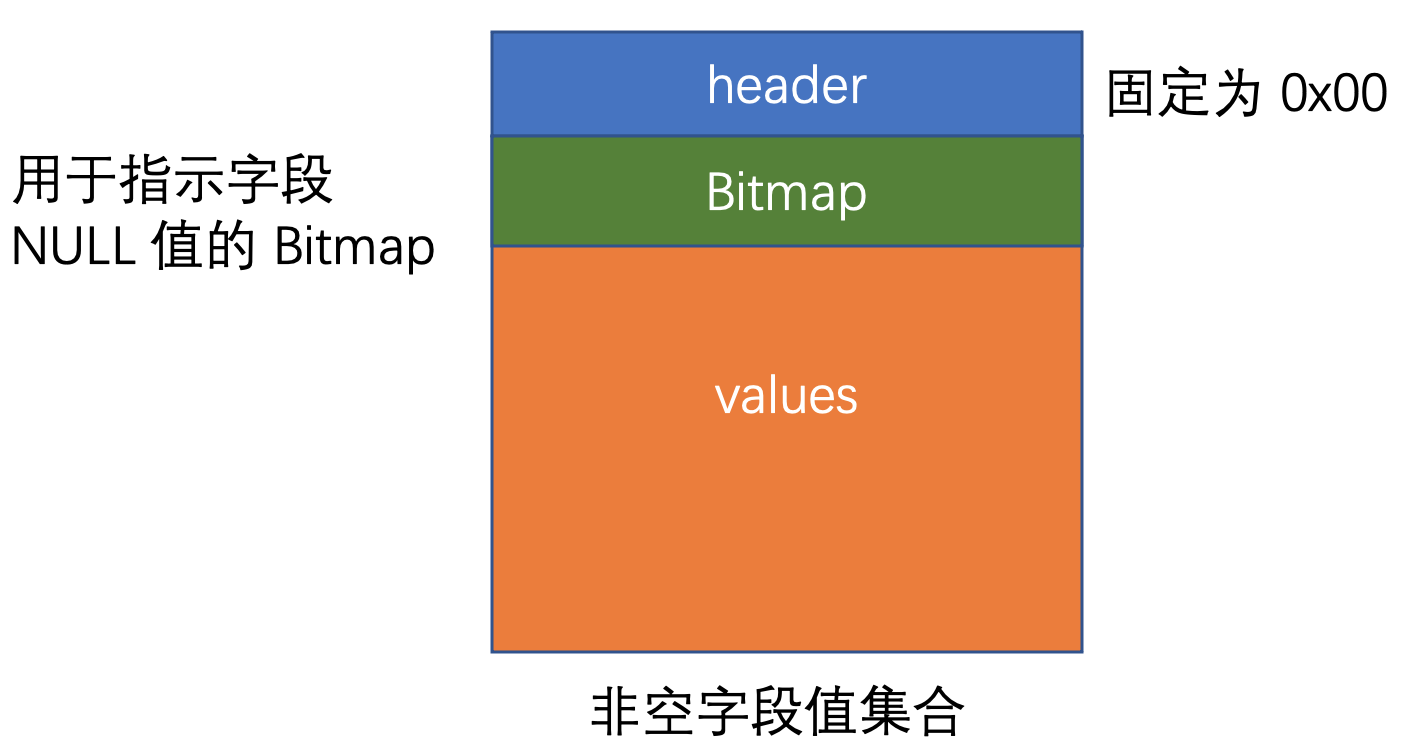
若查询结果有 N 个数据行, 那么总共会有 N 个这样的数据包, 客户端解析包结构便可以获取此次查询的结果
5.6 Binlog 与 Replication 协议
Binlog 即 Binary Log, 是在 MySQL 3.23.14 中引入的一项功能, Binlog 记录了 MySQL 数据变更的详情, Binlog 自推出以来, 总共经历了 4 个版本, 最初的 Binlog 是 Statement-Based Binlog, 日志中记录了所有(可能)造成数据变更的 SQL 操作语句, 如 INSERT、UPDATE 等, 之所以说「可能」是因为比如 DELETE 语句如果没有匹配的记录则执行后数据库中的数据不会发生任何变更, 在 MySQL 5.1 之后, 引入了 Row-Based Binlog, 所谓 Row-Based Binlog 是在日志中记录每次 SQL 操作前后数据行所产生的 Diff, Binlog 很大的应用场景是用来做数据同步, 比如 MySQL 的主从同步或者是同步 MySQL 数据到其它数据中间件, 如 Redis、ES、MongoDB, 或者是对数据库进行迁移等, 其实 Statement-Based Binlog 和 Row-Based Binlog 各有优缺点, 对于 Statement-Based Binlog 来说, 它的好处是占用空间小, 比如我们对数据库的 10000 条数据做更新操作, 在 Statement-Based Binlog 中只需记录一条 UPDATE 语句即可, 而在 Row-Based Binlog 中则需要详细记录下这 10000 条数据的 Diff 详情, 对于主从同步场景, 如果我们以状态机的观点去看待两种不同的日志格式, 可以知道 Statement-Based Binlog 实际上是记录了状态机的状态变换详情, 而 Row-Based Binlog 则是记录了状态机前后的状态详情, Statement-Based Binlog 虽然占用体积小, 但有一个问题是它不能保证所有的变更都一定会 100% 地表达出来, 一个典型的例子便是如果执行的 SQL 语句中包含了 RAND() 函数, 那么 Slave 解析 Binlog 并执行该条语句时并不能保证执行结果一定与 Master 相同, 而 Row-Based Binlog 则可以完全规避这个问题, 使数据 100% 可以被还原出来
当然, 鉴于单独使用以上两种日志格式存在的缺点, MySQL 在之后的版本中又推出了 Mixed 格式的 Binlog, Mixed 格式摘取了前两种 Binlog 的优点, 默认使用 Statement-Based Binlog 格式来记录, 而在必要时刻转换为 Row-Based Binlog 格式, 这样既减少了 Binlog 文件的体积, 又避免了单纯的 Statement-Based Binlog 无法 100% 精确还原数据的问题
基于 Binlog, 开源社区衍生出了很多数据迁移工具, 如 go-mysql、Canal 等, 这里简述一下基于 Binlog 的 Replication 协议, 如果你需要更详细的信息以便开发类似的工具可以参看 MySQL 技术手册以及开源社区已有的项目代码
当客户端向服务端发送 COM_BINLOG_DUMP 指令后, MySQL 服务端便开始向客户端以字节流的形式传送 Binlog, 对于 Statement-Based Binlog, 日志是由事件序列构成的, 事件有多种类型, 具体的事件列表可以参看 Binlog-EventType, MySQL 服务端在传送 Binlog 时, 会在每个事件前面添加 0x00 这样一个分界符字节, 每个事件都由事件头和主体构成, 主体进一步分为固定部分和可变部分, 因此也可以理解为事件是由三部分构成的, 事件头(EventHeader), 主体的固定部分(PostHeader) 和主体的可变部分(Payload), 所有的 Binlog 文件都是以固定的 4 字节开头, 这 4 个字节分别是 0xfe 0x62 0x69 0x6e, 即 0xfe 'b''i''n', 在解析 Binlog 数据时, 如果开头不是这 4 个字节可以认为数据是非法的或者文件已损坏, 在 Binlog 文件中, 第一个事件比较特殊, 在早期版本的 MySQL 中, 第一个事件是 START_EVENT_V3 事件, 记录了 Binlog 的版本, MySQL 服务端的版本以及文件创建的时间戳等, 在 MySQL 5.0 之后, 使用 FORMAT_DESCRIPTION_EVENT 来替代 START_EVENT_V3 结构, FORMAT_DESCRIPTION_EVENT 拥有比 START_EVENT_V3 更丰富的字段信息, 并具有扩展性, 除了在 START_EVENT_V3 中的诸如 Binlog 版本、MySQL Server 版本以及时间戳之外, 还描述了每种事件类型对应的事件头(EventHeader)的长度, 客户端可以根据这些信息来解码读取对应的事件类型, 在 MySQL 服务端, Binlog 是以普通二进制文件存放的, 它们的名字形如 mysql-bin.NNNNNN(如 mysql-bin.000001、mysql-bin.000002 等)每个 Binlog 文件都有最大限制, 可以在 MySQL 的配置文件中设置单个 Binlog 的最大长度, 当 Binlog 文件长度超过特定的限制后, MySQL Server 便会创建一个新的 Binlog 文件并继续保存相应的日志(另外当执行 FLUSH LOGS 时也会新创建 Binlog 文件), 除了日志文件本身, MySQL Server 还维护了一个 mysql-bin.index 文件, 该文件是用文本形式存放的, 记录了当前已有的 Binlog 文件名
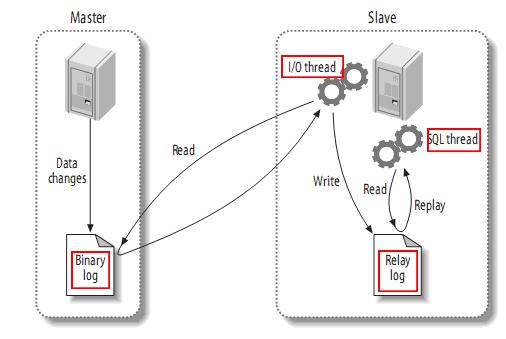
整个主从同步过程是这样的, MySQL Server 当有数据变更时会将数据按设定的格式写入到形如 mysql-bin.NNNNNN 的文件中, 当接收到 Slave 的 DUMP 请求后, Server 端便开启 Dump Thead, 用于并发地读取 Binlog 文件内容并发送给 Slave, 而 Slave 设置了一个 IO Thread 来接收客户端发来的字节流, 并其写入到 Relay log 中, Relay log 与 Binlog 的格式完全相同, 所以 IO Thread 其实并不会对数据做任何修改, 只是单纯地读取字节流并写入本地文件, Relay log 设置的目的是为了缓冲, 若没有 Relay log, 则 Slave 必须以完全同步的方式接收并执行 Master 发来的数据, 同时在 Slave 端也设置了一个 SQL Thread 它并发地读取 Relay Log, 并将数据应用到数据库中, 整个过程可以用如下的图示来描述(图片来自于 Alibaba/Canal))
5.7 总结
- MySQL 客户端/服务端可使用多种方式通信, 如 TCP、UNIX Domain Socket 等
- MySQL 交互协议的 wire_type 只有两类, 即数字和字符串, 这两类下又可划分为多个子类型, 所有的数字类型都是以小端字节序传输
- MySQL 客户端/服务端之间以 Packet 作为逻辑单位进行交互, 每个 Packet 的最大长度为 16MB, 若交互数据长度超过此限制, 则需要进行分片传输, 每个 Packet 都拥有与一个 sequence_id, 并且 sequence_id 会在交互次数足够多后重复
- MySQL 客户端/服务端在连接建立之后首先需要进行握手/鉴权, 认证通过以后便可以进行真正的数据库操作交互
- MySQL 的 SQL 语句分为 Immediate SQL 和 Prepared SQL, 对于 Immediate SQL, 交互协议使用文本格式, 对于 Prepared SQL 使用 Binary 格式, 并引入 Bitmap 来优化传输字段的 NULL 值表示
- MySQL 的 Binlog 分为 Statement-Based Binlog、Row-Based Binlog 以及 Mixed-Binlog, Statement-Based Binlog 虽然占用空间小, 但不能保证完全无误地描述数据的变更, 而 Row-Based Binlog 可以 100% 还原数据变更详情, Binlog 可以用来做主从同步、数据库迁移或同步 MySQL 数据到其它数据中间件, 如 Redis、ES、MongoDB 等