查找是计算机科学的一个基本的问题, 一般说来, 无论具体的实现算法如何, 查找方法都可以归结为两类, 基于比较的查找和基于哈希的查找, 所谓基于比较的查找, 即是在特定的数据结构中按某种策略依次将关键字与该数据结构中的元素进行比较, 对于线性表顺序查找, 比较的结果有等于和不等于两类, 对于树形结构的查找, 比较的结果有大于、小于和等于三类, 而基于哈希的查找, 则是采用一个映射函数, 将待查找的关键字作为该函数的因变量, 函数值即为所要查找的目标的元素的地址, 相比于基于比较的查找, 基于哈希的查找效率很高, 本文首先从理论角度讨论 HashTable 相关概念及算法, 然后给出 Redis 和 Golang 对于 HashTable 的底层实现细节
4.1 HashTable 的定义及算法
哈希又称散列、杂凑, 是一种将查找关键字和目标元素的存储地址建立了映射关系的数据结构, 哈希表通常情况下可以在 的复杂度内实现对元素的增删改查操作, 相比于线性表和树形结构, 哈希表具有极高的查询效率, HashTable 的原理比较简单, 但是要构造一个高效率的 HashTable 并不是一件容易的事情, 其中 函数 的确定以及冲突的解决方法是对 HashTable 效率影响最大的两个因素
哈希函数是从关键字集合到地址集合的映射, 通常来说, 关键字集合往往远远大于地址集合, 因此哈希函数 通常是一个压缩映射, 这从理论上讲就不可避免地会产生冲突, 所谓哈希冲突即是两个不同的关键字, 经过哈希函数映射之后得到了相同的地址, 即
这时就要采取某种策略来解决冲突, 当关键字集合中存在哈希冲突的元素时, 哈希表的查询效率就会一定程度地下降, 因此一个高性能的 HashTable 就应尽可能地避免冲突的实现, 换句话说, 我们希望哈希函数 能尽可能地将元素映射到随机且均匀的位置上, 哈希函数的构造方法有很多
-
直接定址法
直接定址法是直接取关键字或者关键字的某个线性函数作为哈希函数, 对于直接定址法来说, 哈希像和原像的数目是相等的, 此时哈希函数是一个单射, 因此使用直接定址法是不会产生哈希冲突的, 例如普通的数组在这种意义上就可以看做是一个简单的 HashTable, 下标和其元素的地址之间就存在一一对应的关系, 但在实际场景中直接定址法能应用的场景很少
-
平方取中法
平方取中法在使用的时候若关键字不是数字类型则需要先转换为数字类型, 例如可以使用 码, 然后将数字进行平方运算, 并取其中的 位作为哈希函数值, 平方取中法是基于一个数的平方与数字的各个数位都有关联来考虑的, 这样可以在一定程度上让哈希值更为随机
-
折叠法
折叠法是将关键字进行分段, 然后求和以得到哈希函数值, 折叠法进一步又可以分为两类, 其中第一类是简单顺序的分段然后求和, 第二类则是在分段的时候变换方向, 然后再求和
-
取余法(又称除留余数法)
取余法是用的比较多的哈希方法, 假设哈希表的表长为 , 则取余法的哈希函数可以定义为
取余法的一个关键参数是 , 选择的不好将会导致冲突的增加, 一般在工程实践中都是取 为质数, 可以降低冲突的概率
-
随机数法
随机数法也是一种在实际应用中比较常用的哈希方法, 基于它实现的哈希表的性能取决于所应用的随机数算法是否足够均匀
在实际的应用中, 有的时候为了使得结果更为随机, 可能同时采取以上方法中的几种, 具体需要看问题的场景, 另外哈希函数也不能设计的过于复杂, 否则会影响哈希表的读写效率
哈希表冲突的解决方法也有多种, 一般说来用的比较多的有开放定址法、链地址法(拉链法)、再哈希法等
-
开放定址法
开放定址法的思路是当关键字经由哈希函数映射得到的地址与其它元素的映射后的地址冲突时则相对该地址做地址偏移, 可以用如下的表达式来描述
其中 length 是哈希表的表长, 为偏移量序列, 根据 数列取值方式的不同, 开放定址法可以进一步分为线性探测再、平方探测再、伪随机探测再, 其中线性探测再 时, 的取值为 1, 2, 3.. m-1; 平方探测再 Hash 时, 的取值为 , , , .., 因为这里的探测是分别向左右两个方向展开进行的, 因此 ; 而伪随机数探测时, 便是一个伪随机数序列. 开放定址法实际上存在一些弊端, 容易产生一个二次聚集的问题, 假设 、、 地址上都已经有元素了, 则使用线性探测再 Hash 的开放定址法时, 对于映射到以上 3 个地址的元素都会尝试将元素放到 地址上, 换句话说, 解决冲突的同时又产生了冲突, 但线性探测再 Hash 的好处是只要哈希表未满, 便一定能找到一个空余位置放下此次欲插入的元素, 而平方探测再 Hash 的问题是即便哈希表是未满的状态, 它也可能永远找不到此刻空余的地址, 对于伪随机数探测再 Hash 则要看伪随机数的具体数据概况
-
链地址法(拉链法、Hash 桶法)
在开放定址法中, 当发生冲突时需要重新对位置进行偏移再判断新位置是否冲突, 直到找到一个不冲突的位置为止, 这个过程比较耗时, 而链地址法则是要解决这个问题, 在链地址法中, 对于每个映射位置设置一个单链表, 将所有映射到该位置的元素都插入到这个链表中, 因此省去了开放定址法需要对位置进行偏移探测的工作, 使用链地址法解决冲突的哈希表在最坏情况下, 查询效率为 , 此时所有的元素都映射到完全相同的位置上, 各个元素之间串联为一个单链表, 此时哈希表便退化为了线性表
4.2 Golang map 的实现
以上我们讨论了 HashTable 的定义及算法, 接下来我们来看两个业界实际应用中的 HashTable 的实现, Go 语言内置了 map 数据结构, map 的底层便是一个 HashTable, Go 语言的 map 的使用非常简易, 但其内部实现相对比较复杂, Go 语言的 Runtime 使用了多个数据结构来实现 HashTable, 本文基于 go version go1.13.1 darwin/amd64 来讨论 Golang 对于 HashTable 的底层实现
4.2.1 Go map 的底层结构
Go map 在语言底层是通过如下的抽象结构来表征, 其位置在 go/src/cmd/compile/internal/types/type.go
// Map contains Type fields specific to maps.
type Map struct {
Key *Type // Key type
Elem *Type // Val (elem) type
Bucket *Type // internal struct type representing a hash bucket
Hmap *Type // internal struct type representing the Hmap (map header object)
Hiter *Type // internal struct type representing hash iterator state
}
前两个字段分别为 key value, 由于 go map 支持多种数据类型, go 会在编译期推断其具体的数据类型, Bucket 是哈希桶, Hmap 表征了 map 底层使用的 HashTable 的元信息, 如当前 HashTable 中含有的元素数据、桶指针等, Hiter 是用于遍历 go map 的数据结构, 将在下文中讨论
Hmap 的具体化数据结构位于 src/runtime/map.go 中, hmap 结构描述了 Go map 的关键信息
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
其中 count 字段表征了 map 目前的元素数目, 当使用 len() 函数获取 map 长度时, 返回的便是 count 成员的值, 因此 len() 函数作用于 map 结构时, 其时间复杂度为 , flag 字段标志 map 的状态, 如 map 当前正在被遍历或正在被写入, B 是哈希桶数目以 2 为底的对数, 在 go map 中, 哈希桶的数目都是 2 的整数次幂(这样设计的好处是可以是用位运算来计算取余运算的值, 即 N mod M = N & (M-1)), noverflow 是溢出桶的数目, 这个数值不是恒定精确的, 当其 B>=16 时为近似值, hash0是随机哈希种子, map创建时调用 fastrand 函数生成的随机数, 设置的目的是为了降低哈希冲突的概率, buckets 是指向当前哈希桶的指针, oldbuckets 是当桶扩容时指向旧桶的指针, nevacuate 是当桶进行调整时指示的搬迁进度, 小于此地址的 buckets 是以前搬迁完毕的哈希桶, 而 mapextra 则是表征溢出桶的变量
在讨论 mapextra 结构之前我们先来看 bmap, 即哈希桶的结构, 由于 go map 的 key 和 elem 可以有多种数据类型, 因此哈希桶的数据类型也会随着 key 和 elem 数据类型的不同而不同, 具体的数据类型是在编译期确定的, 因此 bmap 在 go 的源码中没有显式定义出来, 对 bmap 的操作也是通过计算地址偏移量来实现的, 具体的函数位于 src/cmd/compile/internal/gc/reflect.go, 通过该函数我们也可以还原出 bmap 的结构
type bmap struct {
topbits [8]uint8
keys [8]keytype
elems [8]elemtype
//pad uintptr(新的 go 版本已经移除了该字段, 我未具体了解此处的 change detail, 之前设置该字段是为了在 nacl/amd64p32 上的内存对齐)
overflow uintptr
}
bmap 表征了 go map 哈希桶的结构, 其中 topbits 是键哈希值的高 8 位, keys 存放了哈希桶中所有键, elems 存放了哈希桶中的所有值, overflow 是一个 uintptr 类型指针, 存放了所指向的溢出桶的地址, go map 的每个哈希桶最多存放 8 个键值对, 当经由哈希函数映射到该地址的元素数超过 8 个时, 会将新的元素放到溢出桶中, 并使用 overflow 指针链向这个溢出桶, 这里有一个需要注意的点是在哈希桶中, 键值之间并不是相邻排列的, 这是为了保证内存对齐
现在来看 mapextra 结构, 其数据结构定义为
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// type as containing no pointers. This avoids scanning such maps.
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
当一个 map 的 key 和 elem 都不含指针并且他们的长度都没有超过 128 时(当 key 或 value 的长度超过 128 时, go 在 map 中会使用指针存储), 该 map 的 bucket 类型会被标注为不含有指针, 这样 gc 不会扫描该 map, 这会导致一个问题, bucket 的底层结构 bmap 中含有一个指向溢出桶的指针(uintptr类型, uintptr指针指向的内存不保证不会被 gc free 掉), 当 gc 不扫描该结构时, 该指针指向的内存会被 gc free 掉, 因此在 hmap 结构中增加了 mapextra 字段, 其中 overflow 是一个指向保存了所有 hmap.buckets 的溢出桶地址的 slice 的指针, 相对应的 oldoverflow 是指向保存了所有 hmap.oldbuckets 的溢出桶地址的 slice 的指针, 只有当 map 的 key 和 elem 都不含指针时这两个字段才有效, 因为这两个字段设置的目的就是避免当 map 被 gc 跳过扫描带来的引用内存被 free 的问题, 当 map 的 key 和 elem 含有指针时, gc 会扫描 map, 从而也会获知 bmap 中指针指向的内存是被引用的, 因此不会释放对应的内存
Go 的 map 结构可以用如下所示的结构图来表征
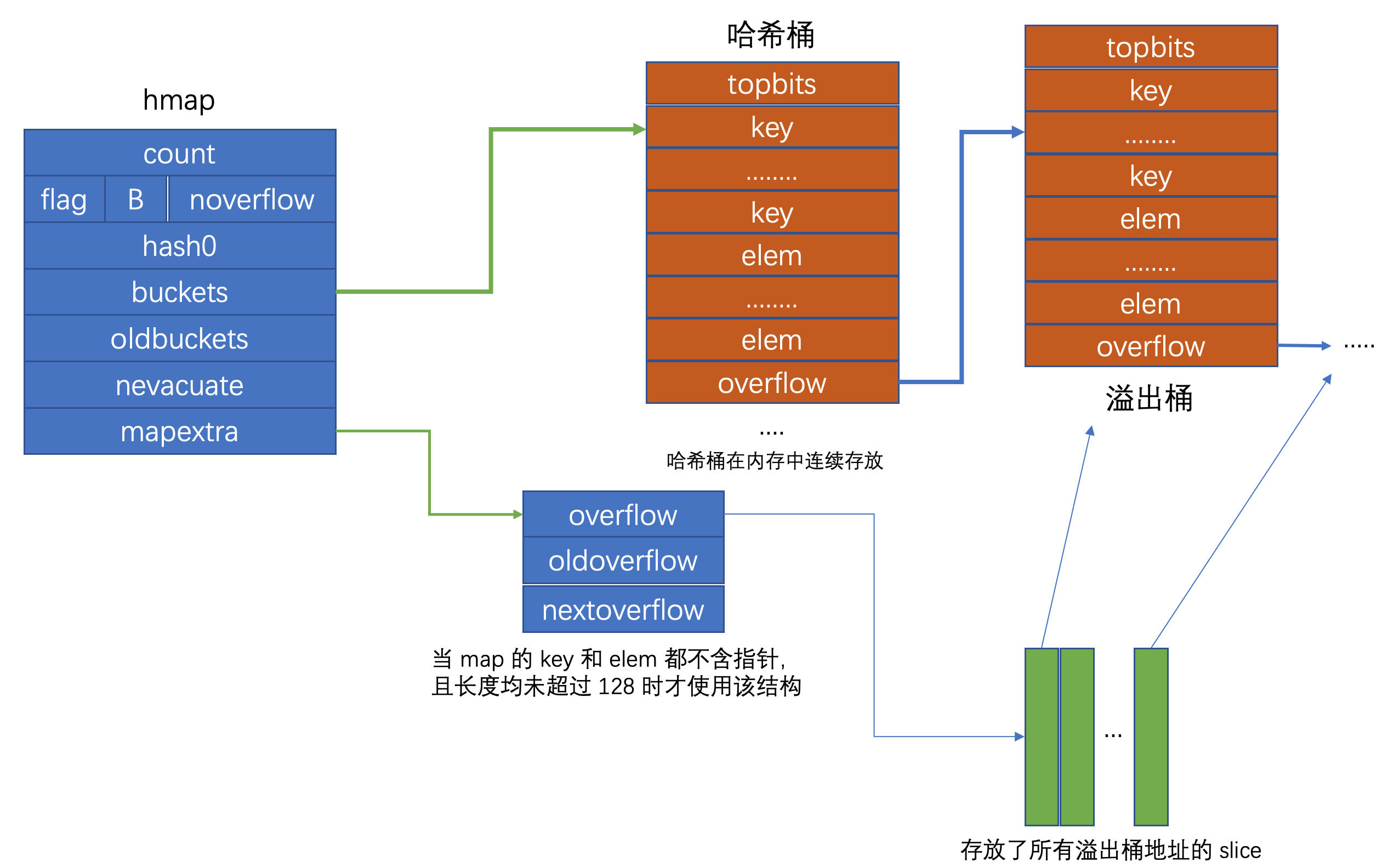
hmap 结构相当于 go map 的头, 它存储了哈希桶的内存地址, 哈希桶之间在内存中紧密连续存储, 彼此之间没有额外的 gap, 每个哈希桶最多存放 8 个 k/v 对, 冲突次数超过 8 时会存放到溢出桶中, 哈希桶可以跟随多个溢出桶, 呈现一种链式结构, 当 HashTable 的装载因子超过阈值(6.5) 后会触发哈希的扩容, 避免效率下降
4.2.2 Go map 的查找
当要根据 key 从 map 中查询对应的 elem 时, 在 go 有两种写法, 一种是直接取值, 例如我们定义 hash := make(map[int]int), 则可以使用 s := hash[key], 也可以使用 s, ok := hash[key], 第一种写法无论 key 是否存在于 map 中, s 都会获取一个返回值, 而当 key 不存在时会返回对应类型的零值, 而第二种写法中, ok 变量可以标识此次是否从 map 中真正的获取到了 key 所对应的 elem, 在 go 语言底层, 这两种写法实际会调用两个不同函数, 它们都位于 src/runtime/map.go 中, 分别调用 mapaccess1 和 mapaccess2 函数, 这两个函数的内部逻辑几乎是一样的, 第二个相比于第一个仅仅多了一个是否查询到的标志位, 我们只来分析 mapaccess1 函数即可, go map 中使用了 aes 和 memhash 两类哈希, 当运行架构支持 aes 哈希时会优先使用 aes 作为 HashFunc, 具体的判定逻辑在 src/runtime/alg.go 的 alginit() 函数中, 当要 map 中查询一个元素时, go 首先使用 key 和哈希表的 hash0, 即创建 map 时生成的随机数做哈希函数运算得到哈希值, hmap 中的 B 表征了当前哈希表中的哈希桶数量, 哈希桶数量等于 , 这里 go 使用了我们在第一节提到的除留余数法来计算得到相应的哈希桶, 因为桶的数量是 2 的整数次幂, 因此这里的取余运算可以使用位运算来替代, 将哈希值与桶长度减一做按位与即得到了对应的桶编号, 当前这里的桶编号是一个逻辑编号, hmap 结构中存储了哈希桶的内存地址, 在这个地址的基础上偏移桶编号*桶长度便得到了对应的哈希桶的地址, 接下来进一步在该哈希桶中找寻 key 对应的元素, 比较的时候基于哈希值的高 8 位与桶中的 topbits 依次比较, 若相等便可以根据 topbits 所在的相对位置计算出 key 所在的相对位置, 进一步比较 key 是否相等, 若 key 相等则此次查找过程结束, 返回对应位置上 elem, 若 key 不相等, 则继续往下比较 topbits, 若当前桶中的所有 topbits 均与此次要找到的元素的 key 的哈希值的高 8 位不相等, 则继续沿着 overflow 向后探查溢出桶, 重复刚刚的过程, 直到找到对应的 elem, 或遍历完所有的溢出桶仍未找到目标元素, 此时返回该类型的零值
4.2.3 Go map 的插入/更新
go map 的插入和 go map 的查找过程类似, 在底层是调用 src/runtime/map.go#mapassign 函数实现的, 插入的具体过程是首先根据 key 和哈希表的 hash0 采用哈希算法(aes/memhash)获得哈希值, 然后使用哈希值与哈希桶数目使用位运算取余获得哈希桶编号, 接下来依次遍历哈希桶中的 topbits 与此次计算的哈希值的高 8 位进行对比, 若遍历到的 topbits 为空, 则临时记录下该位置, 然后继续向后遍历, 整个遍历的优先查找该 key 在 map 中是否存在, 若找到哈希值的高 8 位与哈希桶的 topbits 相等则进一步比较对应位置的 key, 若 key 也相等, 则此时更新该 key 对应的 elem, 在源码中当更新完成后使用 goto 语句直接跳转到函数最后, 更新 hmap 的标志位, 移除正在写入的标识并返回 elem 对应的指针, 在 go map 写入的过程中, 若当前哈希桶未找到 topbits 与哈希值高 8 位相等的, 则沿着 overflow 继续向后遍历溢出桶, 当遍历到最后, 如果没有找到相等的 key, 若遍历的过程中找到空位, 则将新建的 k/v 插入到该空位上, 否则意味着当前的所有哈希桶包括溢出桶在内都已经存满元素了, 此时要判定是否进行 HashTable 的扩容, HashTable 若要扩容需要满足一定条件, 如当前没有正在扩容并且 HashTable 的装载因子已经超过 6.5 了, 或者当前的溢出桶数目过多时会触发 HashTable 的扩容, 当 HashTable 扩容完毕后, 写入操作会 goto 到一开始, 重复上述过程, 反过来, 若当前没有达到 HashTable 扩容的条件, 则此时只是简单地再生成一个溢出桶, 然后将 key 和 elem 放入新的溢出桶的第一个位置上, 完成此次的写入操作
4.2.4 Go map 的删除
go map 的删除与查找/插入/更新操作的过程类似, 都是通过哈希映射、比较 topbits、依次遍历哈希桶溢出桶、计算 key/elem 偏移量等过程来定位元素位置, 当找到元素后, 则清空的对应的内存位置的数据, 有的元素是以指针形式存储的(如长度超过 128 的 key/elem), 则定位到该指针对应的内存将数据清空
4.2.5 Go map 的扩容
随着向 HashTable 中插入的元素越来越多, 哈希桶的 cell 逐渐被填满, 溢出桶的数量可能也越来越多, 此时哈希冲突发生的频率越来越高, HashTable 的性能将不断下降, 为了解决这个问题, 此时需要对 HashTable 做扩容操作, 对于任意一个 HashTable 来说, 装载因子表征了此时 HashTable 中存放元素的状况, 其一般的定义为
在 go map 中, 针对 go map 的特定数据结构, 其装载因子等于 k/v 对数目除以哈希桶的数目(含溢出桶), golang 规定当该定义下的装载因子达到 6.5 时便需要触发 map 的扩容, go map 扩容和策略共有两种, 除了刚刚所说的装载因子达到 6.5 之外, 若溢出桶过多也会触发 map 的扩容, 这是基于这样的考虑, 向 map 中插入大量的元素, 哈希桶将逐渐被填满, 这个过程中也可能创建了一些溢出桶, 但此时装载因子并没有超过设定的阈值, 然后对这些 map 做删除操作, 删除元素之后, map 中的元素数目变少, 使得装载因子降低, 而后又重复上述的过程, 最终使得整体的装载因子不大, 但整个 map 中存在了大量的溢出桶, 因此当溢出桶数目过多时, 即便没有达到装载因子 6.5 的阈值也会触发扩容, 若装载因子过大, 说明此时 map 中元素数目过多, 此时 go map 的扩容策略为将 hmap 中的 B 增一, 即将整个哈希桶数目扩充为原来的两倍大小, 而当因为溢出桶数目过多导致扩容时, 因此时装载因子并没有超过 6.5, 这意味着 map 中的元素数目并不是很多, 因此这时的扩容策略是等量扩容, 即新建完全等量的哈希桶, 然后将原哈希桶的所有元素搬迁到新的哈希桶中
分析 go map 的插入和删除函数的源码可知, map 的扩容是发生在插入和删除的过程中, 扩容的具体逻辑位于 src/runtime/map.go#growWork, go map 的扩容类似于 redis, 都是采用渐进式扩容, 避免一次性对大 map 扩容造成的区间性能抖动, go 扩容的基本步骤是首先根据扩容条件(装载因子 >= 6.5 或 溢出桶数目太多), 而确定扩容后的大小, 然后创建该大小的新哈希桶, 这时会将 hmap 中的 buckets 指针指向新创建的哈希桶, 而原先的哈希桶地址则保存在 oldbuckets 指针中, 该段逻辑位于 src/runtime/map/go#hashGrow, 该函数只是用于为新的哈希桶创建存储空间, 并未开始搬迁, 具体的搬迁逻辑位于 src/runtime/map.go#evacuate 中, 若是因为溢出桶数目过多造成的扩容, 则扩容是等量扩容, 整个过程是将原 Bucket 中的所有元素迁移到新的等量的 Bucket 中, 在迁移的过程中, 哈希桶(非溢出桶)的相对位置不会发生改变, 即原先位于 N 号 Bucket 的元素会映射到新的 N 号 Bucket 位置上, 而若是翻倍扩容, 则元素会被平均(此处不是数学意义上的严格平均, 其具体分流逻辑是用哈希值与原 Bucket 数目做逻辑与运算, 取决于 HashFunc 的该位是否足够平均)分流到两段上, 在 go 中每次只搬迁两个 Bucket, 当所有元素都搬迁完毕之后, hmap 的 oldbuckets 指针会被设置为 nil, 因此 oldbuckets 指针是否为 nil 可以作为当前 map 是否处于扩容状态的一个标志
4.2.6 Go map 的遍历
go map 的遍历原本是一件比较简单的事情, 外层循环遍历所有 Bucket, 中层循环横向遍历所有溢出桶, 内层循环遍历 Bucket 的所有 k/v , 若没有扩容逻辑的话, 以上所述的 3 层循环即可完成 map 的遍历, 但由于扩容逻辑的存在, 使得 map 遍历复杂性略微有所增加, map 的迭代器由如下结构来表征
// A hash iteration structure.
// If you modify hiter, also change cmd/compile/internal/gc/reflect.go to indicate
// the layout of this structure.
type hiter struct {
key unsafe.Pointer // Must be in first position. Write nil to indicate iteration end (see cmd/internal/gc/range.go).
elem unsafe.Pointer // Must be in second position (see cmd/internal/gc/range.go).
t *maptype
h *hmap
buckets unsafe.Pointer // bucket ptr at hash_iter initialization time
bptr *bmap // current bucket
overflow *[]*bmap // keeps overflow buckets of hmap.buckets alive
oldoverflow *[]*bmap // keeps overflow buckets of hmap.oldbuckets alive
startBucket uintptr // bucket iteration started at
offset uint8 // intra-bucket offset to start from during iteration (should be big enough to hold bucketCnt-1)
wrapped bool // already wrapped around from end of bucket array to beginning
B uint8
i uint8
bucket uintptr
checkBucket uintptr
}
其中 src/runtime/map.go#mapiterinit 函数来初始化以上结构体, 然后调用 src/runtime/map.go#mapiternext 来实现具体的遍历逻辑, 由于 map 扩容逻辑的存在, map 的遍历是无序的, 而实际上即便我们在代码中硬编码一个固定的 map, 其所有的 k/v 都以常数写在源码中, 也不对其做插入/删除/更新操作, 其每次遍历的结果仍然是不同的, 这是因为 go 随机设置了遍历起点, 不仅起始 Bucket 是随机的, 对于 Bucket 中的起始 cell 也是随机的(这样做似乎是为了规避程序员故意使用这个 map 的顺序?), map 在迭代过程中, 需要检查 map 的状态, 如果 map 当前正处于扩容状态, 则需要检查遍历到的 Bucket, 若 Bucket 尚未搬迁, 则需要去该 Bucket 对应的 oldBucket 里遍历元素, 并且这里要注意因为 oldBucket 中的元素可能会分流到两个新 Bucket 中, 因此在遍历时只会取出会分流到当前 Bucket 的元素, 否则元素会被遍历两次, 具体细节可以看 mapiternext 函数的代码
4.3 Redis HashTable 的实现
我们基于 Redis 3.0 讨论其 HashTable 的实现, Redis 的主要功能是作为一个键值数据库, 因此 HashTable 是 Redis 的一个核心数据结构, 从实现思路上讲 Redis HashTable 和 go map 几乎相同, Redis HashTable 实现的代码位于 src/dict.h 和 src/dict.c, Redis 的 HashTable 由 dictht 结构体表征
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
其中 table 是指向 dictEntry 数组的指针, 其结构为
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
dictEntry 存放了哈希表的一个 k/v 对, 并以 next 指针指向下一个 k/v dictEntry 结构, 这里的 next 指针相当于 go map 哈希桶的 overflow 指针, 在 Redis 中同样是采用链地址法来处理哈希冲突, 而 dictht 中的 size 字段表征了哈希表的长度, sizemask 字段是哈希表长度的掩码, 这里与 go map 中是相同的, 都是为了使用位运算来替代取余运算, 以便确定一个 k/v 放入哈希表的哪个结点中, 而 used 字段则表征了当前已使用的哈希表结点数量, Redis 内部的字典结构使用了两个 HashTable 来实现, 其字典结构的定义为
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;
type 字段是 dictType 结构体类型的指针, 该结构体定义了与 HashTable 相关的函数, 我们主要关注后 3 个字段, 其中 dictht 即是哈希表数据, Redis 之所以设置两个哈希表其目的是为了用于 reHash, 与 go map 的扩容相对应
4.3.1 Redis HashTable 的插入
Redis HashTable 的数据结构相比于 go map 要简单一些, Redis 使用 MurmurHash 算法来作为哈希函数, 得到 Hash 值之后与 sizemask 做逻辑与运算(等价于用哈希值对哈希表长取余), 然后确定元素要存放的哈希结点, 若该结点原先已有元素, 则相当于发生了冲突, 这时新建一个结点, 将其链接到表头即可
4.3.2 Redis HashTable 的查找/更新/删除
由于其逻辑都比较类似, 因此这里不一一展开讨论每个操作的细节, 操作过程都是根据哈希函数计算 Key 的哈希值, 然后与 sizemask 做逻辑与确定元素对应的哈希结点, 然后沿着该结点对应的链表顺序遍历即可
4.3.4 Redis HashTable 的扩容/缩容
dict 结构的 dictht 字段是一个含有两个哈希表对象的数组, 普通情况下只有 0 号元素对应的哈希表处于工作状态, 即对哈希表的查找、插入、更新、删除操作都只针对这一个哈希表, 当此哈希表的负载因子超过 1 时, Redis 会启动扩容过程, 与 go map 类似, Redis 的扩容也不会一次性地进行, 而是采用渐进式的策略避免一次性迁移元素带来的性能抖动, 反过来, 当哈希表的负载因子过小时, 说明此时分配的空间过多, Redis 会启动哈希表的缩容, Redis dict 结构的 dictht 字段存放的两个哈希表即对应 go hmap 中的 buckets 和 oldbuckets, 当扩容启动后, 0 号哈希表将不再插入新的元素, dict 结构中的 rehashidx 字段表征了当前 rehash 的进度, 当哈希表未处于扩容/缩容状态时, 该字段为 -1, 当处于扩容/缩容过程中时, 该字段指示了当前已迁移的元素的编号, Redis 的扩容/缩容的空间分配策略是对于扩容, 则新的哈希表长度是大于等于原哈希表已使用的空间长度的两倍的最小的 , 例如原先使用了 6 个哈希结点, 则扩容后的哈希表长度将为 16, 因为 16 是最小的大于等于 6*2 的 , 而对于缩容, 则新的哈希表长度为大于等于原哈希表已使用的空间长度的最小的 , 例如原先已使用了 6 个哈希结点, 则新的哈希表长度为 8, 元素迁移的时机是在对哈希表做插入/查找/删除/更新操作时, 若检查 rehashidx 不等于 -1, 则启动一次 reHash 操作, 在 Redis 内部, 作者封装了一个 ReHash 函数(src/dict.c#_dictRehashStep)
/* This function performs just a step of rehashing, and only if there are
* no safe iterators bound to our hash table. When we have iterators in the
* middle of a rehashing we can't mess with the two hash tables otherwise
* some element can be missed or duplicated.
*
* This function is called by common lookup or update operations in the
* dictionary so that the hash table automatically migrates from H1 to H2
* while it is actively used. */
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}
并这个函数穿插到对哈希表各种操作的函数中, 使得在完成对哈希表各种操作的同时执行 ReHash, 除此之外, 考虑到可能会有长时间未对哈希表有任何操作的情形, 如果只有上述一个条件, 则 ReHash 迟迟不能执行, 当 reHash 是要进行缩容操作时, 这会使得缩容停滞, 冗余的内存迟迟没有释放, 因此在 Redis 中, 也设定了定时执行 ReHash, 具体逻辑在 src/redis.c#incrementallyRehash
/* Our hash table implementation performs rehashing incrementally while
* we write/read from the hash table. Still if the server is idle, the hash
* table will use two tables for a long time. So we try to use 1 millisecond
* of CPU time at every call of this function to perform some rehahsing.
*
* The function returns 1 if some rehashing was performed, otherwise 0
* is returned. */
int incrementallyRehash(int dbid) {
/* Keys dictionary */
if (dictIsRehashing(server.db[dbid].dict)) {
dictRehashMilliseconds(server.db[dbid].dict,1);
return 1; /* already used our millisecond for this loop... */
}
/* Expires */
if (dictIsRehashing(server.db[dbid].expires)) {
dictRehashMilliseconds(server.db[dbid].expires,1);
return 1; /* already used our millisecond for this loop... */
}
return 0;
}
Redis 的 ReHash 是哈希桶(即冲突元素构成的链表)为单位进行的, 每次会将整个链表上的所有元素都重新分配到新的哈希表中, 在 reHash 进行的过程中, 对元素的查找/删除等操作会先后查询旧表和新表, 但插入操作则限制在新表上, 这样使得旧表的元素一定会慢慢减少, 直到所有元素迁移完, 此时 Redis 将 rehashidx 恢复为 -1, 并释放原哈希表的内存, 然后将新表的索引改为 0, 并在 1 号位置上预备建立空白哈希表, 等待下次 reHash 时用
4.4 总结
总的来说, 无论是 Redis 还是 go map, 其对哈希表的实现原理基本相同, 关键点都在于哈希函数、冲突处理、扩容/缩容策略上, 从系统结构上将, Redis 的哈希表要比 go map 相对更为简单一些, 本文的主要目的是讨论哈希表的原理, 尽管哈希表的原理很直观, 但在工程实践上会涉及到比较多的细节, 如何实现一个高性能的 HashTable 是一件富有挑战性的事情, 在 go map 的解析中, 由于涉及一些语言细节, 很多东西没有展开讲, 如果有兴趣可以自行阅读 go map 的源码, 这里做本文所讨论的内容做一个简短的总结
- 哈希表(HashTable)是一种用于查找的数据结构, 对于线性表/树等结构的查找往往采用基于比较的查找方式, 而哈希表则采用哈希函数直接定位地址的方式
- 哈希表的平均操作(插入/更新/删除)的复杂度为 O(1), 最坏情况下为 O(N)
- 哈希表实现的关键在于哈希函数的选择、冲突处理策略和缩容/扩容策略
- go map 根据 CPU 情况选择 aes 或 memhash 作为哈希函数, 冲突处理策略为链地址法(拉链法、哈希桶法)
- go map 的每个哈希桶可以存放 8 个 k/v 对, 哈希桶的起始位置存放了每个元素哈希值的高 8 位, 用于加速定位元素, 桶中的 key 和 elem 分别连续存放, 便于内存对齐, 每个哈希桶都设有 overflow 指针用于指向溢出桶, 哈希桶和溢出桶串联起来形成单链表结构
- go map 定位元素的过程是首先代入哈希函数计算哈希值, 然后与哈希表长取余(用 bitmask 按位与加速选择), 在桶的内部顺序遍历比较哈希值的高 8 位是否相等, 若相等则根据地址偏移量偏移到 key 的位置进一步比较是否相等, 若 key 相等则定位完毕, 否则继续向后比较, 若当前哈希桶未找到对应元素, 则沿着 overflow 指针顺序遍历溢出桶, 重复上述过程, 直到直到目标元素或报告目标不存在
- go map 在当负载因子超过 6.5 或溢出桶过多时启动扩容, 扩容根据导致扩容原因的不同采用等量扩容或翻倍扩容, go map 的扩容不是一个原子性的操作, 而是渐进式的进行, 在对 go map 插入/删除元素的时候会进行元素的搬迁, 每次最多搬迁两个哈希桶的元素
- 由于哈希表扩容的存在, go map 的遍历结果每次不是一样的, 即不保证是顺序的, 并且即便是硬编码的常数 map, 对其进行遍历每次结果也不相同, 原因是启动遍历时, go 会随机选择一个哈希桶, 并在哈希桶中随机选择一个 cell 的位置开始遍历
- 从 hashTable 的原理上来看, go map 不是线程安全的, go map 仅仅在 hmap 的标识位上设置了当前正在遍历/正在写入等标识, 但不会加锁, 因此多个 goroutine 并发对 map 做遍历、插入、删除操作时会 throw 异常
- Redis HashTable 与 go map 的实现原理类似, 也都是用拉链法(哈希桶法)解决哈希冲突
- Redis 的扩容缩容与 go map 类似, 都采用渐进式的方式, 避免一次性的搬迁元素造成性能抖动