IP 协议是互联网最重要的协议之一, IP 是 Internet Protocol 的缩写, 它是 TCP/IP 协议体系的两个主要协议之一, 其正式的协议文档为 1981 年 9 月发布的 RFC 791, 它被设计用来在互连网络之间传输 Packet, IP 协议传输的基本数据单元 (PDU, 协议数据单元) 称为 IP Datagram, IP 协议是主机与主机 (host-to-host) 之间的协议 , 而不是端到端 (end-to-end) 的, 它提供无连接、不可靠、不排序、尽最大努力交付 (best-effort) 的服务, IP 协议是全球异构互连网络都在使用的标准协议, 截止目前, 主要使用的 IP 协议有两个版本, 分别是 IP Version 4 (简称 IPv4) 以及 IP Version 6 (简称 IPv6) [RFC 2460](Deprecated), [RFC 8200], 本文详细讨论 IPv4 的设计与工作原理 (因此文中凡是提到 IP, 如无特别说明, 均代指 IPv4), 有关 IPv6 协议我将在以后的博客中讨论
18.1 IPv4 协议的特点
-
IP 协议在进行数据传输之前, 无需事先建立连接, 即 IP 协议是无连接的协议, 并且 IP 协议是在主机与主机 (host-to-host) 之间传输, 而不是端到端 (end-to-end) 的, 换句话说, IP 协议在某一链路上传输时, 它所关心的并不是将 IP Datagram 传输到最终的目的地, 而是只需要尽最大努力交付到下一个主机或路由器上
-
IP 协议是不可靠, 尽最大努力交付 (best-effort) 的协议, 因此 IP 协议不设置确认机制, 不设置重传机制, 不保证数据一定会送达目的地, 除了在 Header 中设置只针对头部的 Checksum 校验之外, 也没有设置其它的错误控制机制 (IP 协议本身只设置 Header Checksum 这一项错误控制机制, 发生其它错误时可以通过 ICMP 协议 [RFC 792] 向源端报告问题)
-
IP 协议不设排序机制, 即发送方按一定顺序发送, 但接收方最终收到的消息并不保证一定是顺序的
-
IP 协议设置分段机制, 当要传输的消息过长时, 发送方以及传输路径上的任一主机都可以对消息进行分段, 将长消息拆分为多个 IP Datagram, 目的主机收到全部分组后需要重新拼装消息
-
IP 协议位于 OSI 模型体系的第 3 层, 属于网络层协议, 它的相对位置如下所示:
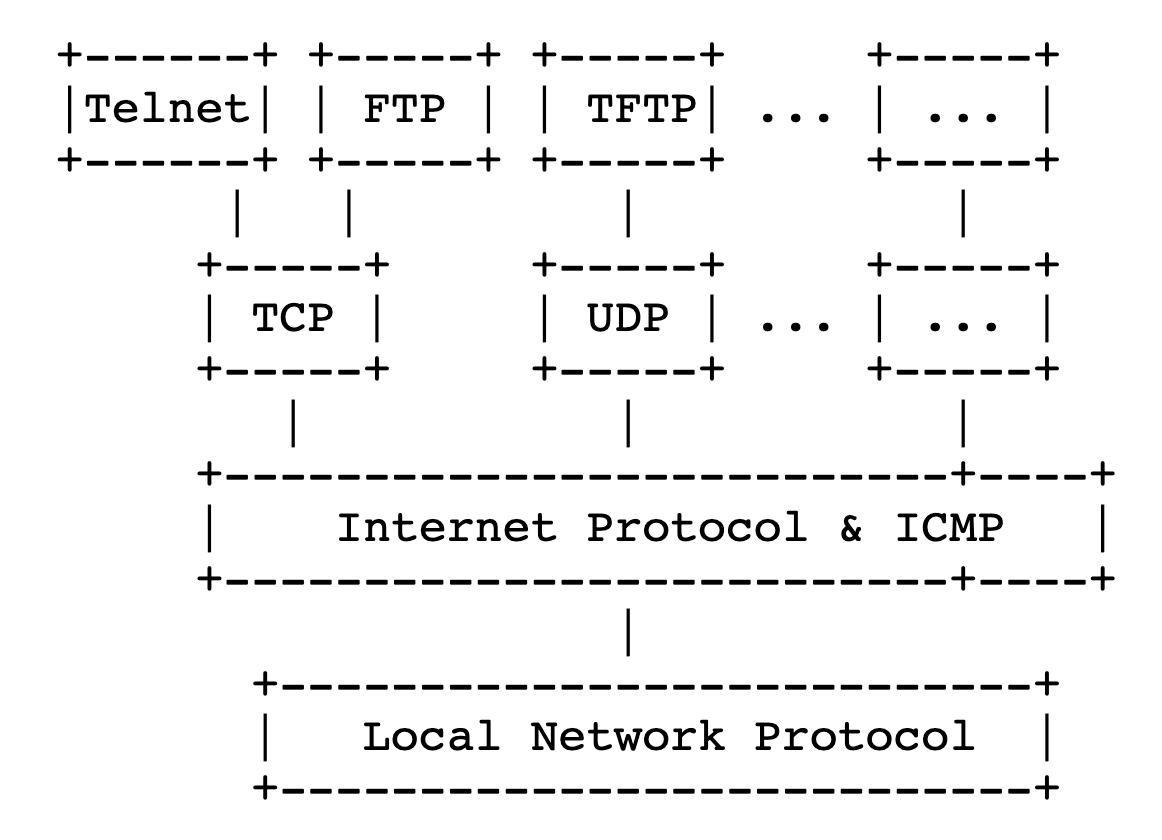
- IP 协议的数据包由 Header 和 Payload 两部分构成, 在发送端, 主机将源 IP 地址设置为自己的 IP 地址, 将期望送达的目的 IP 地址填入到头部的目的 IP 地址字段, 然后发送到本网络的网关, 网关收到 IP Datagram 后分析并剥去 IP Header, 然后根据路由选择算法确定下一跳主机的 IP 地址, 同时更新 Header 的某些参数 (比如 TTL, Checksum 等, 将在下面讨论) 重新构建新的 IP Header, 封装成新的 IP Datagram, IP Datagram 每经过一跳主机(或路由器)都重复上述过程, 中间可能会发生分片等情形, 最终 IP Datagram 到达目的主机
18.2 IPv4 Header 结构

Header 的各个字段的语义如下:
-
Version, 长度为 4 比特, 表征 IP 协议的版本号, 对 IPv4 来说该字段的值为 4
-
IHL, 长度为 4 比特, IHL 是 Internet Header Length 的缩写, 以 4 字节为单位指示 IP Header 的长度, 对于 IPv4 来说, Header 的最小长度为 20 字节, 因此该字段的最小值为 5
-
Type of Service, 服务类型, IETF 在之后将该字段改为 Differentiated Service, 即区分服务, 长度为 8 比特, 该字段用来表达发送端对服务质量的期望程度, 例如可以通过在该字段中设置标志位表达发送方希望该 IP Datagram 低时延 (Low Delay) 的效果送达终端, 或希望以高可靠性 (High Relibility) 的效果送达终端, 但这些都需特定网络或 ISP 的支持, 具体细节可以查看 RFC 791 Section 3.1
-
Total Length, 长度为 16 比特, 顾名思义该字段以字节为单位指示整个 IP Datagram 的长度, 结合 IHL, 我们可以计算出一个 IP Datagram 的数据部分长度为 Total Length - IHL / 4, 因为该字段的长度为 16 比特, 所以可以知道一个 IP Datagram 理论上最大的长度为 2 ^ 16, 即 65535 个字节, 但实际上这么长的 IP Datagram 往往无法保证一定可以被主机或路由器正确的处理, RFC 791 规定所有主机都至少能够处理 576 字节的 IP Datagram, 因此不建议发送超过 576 字节的 IP Datagram, 除非你知晓中途的主机或路由器都可以正确地处理
-
Identification, 长度为 16 比特, 发送方维护一个计数器, 每产生一个 IP Datagram, 计数器的值就加一, 该字段主要用在 IP 分片场景中, 对于分片的 IP Datagram, 它们在逻辑上仍然是一个 IP Datagram, 所有分片的 IP Datagram 的 Identification 值都是相同的, 接收方最终可以根据该字段知晓哪些 IP Datagram 是属于同一个整体的
-
Flags, 长度为 3 比特, 其中最高位为保留位, 目前没有使用, 必须设置为 0, 中间的一位是 DF (Don't Fragment), 当该位为 1 时代表不分片, IP Datagram 在传输过程中, 如果其长度过长, 中间设备无法处理, 但又发现该字段为 1 时, 应丢弃该 IP Datagram, 最后一位是 MF (More Fragments), 当该位为 1 时, 代表当前不是分片的最后一个 IP Datagram, 在之后还有更多的分片, 当该位为 0 时代表当前是分片的最后一个 IP Datagram
-
Fragment Offset, 片偏移, 长度为 13 比特, 当发生 IP Datagram 分片时, 该字段将指示当前分片在原先的整个 IP Datagram 上的偏移量, 以 8 字节为单位, 对于不分片或分片的第一个 IP Datagram, 该字段的值必须为 0
-
Time to Live, 简称 TTL, 长度为 8 比特, 由发送端设置初始值, 在 RFC 791 中, 该字段的语义是一个 IP Datagram 从发出以后所能存活的最长时间, 以秒为单位, IP Datagram 在每经过一个主机或路由器时, 都需要减去路由器处理该 IP Datagram 时所花费的时间, 如果花费时间少于 1s 则按 1s 算, 现在该字段已经被改为跳数, 即每经过一个主机或路由器该字段减去一, 当某个 IP Datagram 的 TTL 字段的值减到 0 时, 必须立即丢弃该分组, 设置该字段的目的是为了防止那些无法被交付到目的地的分组在网络中无限地循环, 造成不必要的资源浪费
-
Protocol, 长度为 8 比特, 用于指示 IP Datagram 携带的数据使用的上层协议类型, 该字段的值为协议的编号, 协议编号由 IANA 维护
-
Header Checksum, 长度为 16 比特, 其值为 IP Header 部分的校验和, 在一定程度上保证 IP 数据的完整性, 接收到 IP Datagram 的主机应检查该字段是否正确, 若不正确应立即丢弃该分组, 另外, 用于每经过一个主机或路由器, Header 部分都会更改 (至少需要更改 TTL), 因此该字段的值每经过一跳都需要重新计算和赋值
-
Source Address, 长度为 32 比特, 源 IP 地址
-
Destination Address, 长度为 32 比特, 目的 IP 地址
-
Options, 拓展字段, 该字段长度可变, 扩展字段可以包含一些可选项, 例如客户端可以利用拓展字段来记录 Datagram 的路由数据等, 具体细节可以见 RFC 791 Section 3.1
-
Padding, 由于 IHL 字段以 4 字节为单位表征 IP Datagram 的 Header 部分的长度, 因此 IP Header 的长度必须是 4 字节的整数倍, 由于 Options 的长度是可变的, 它可能导致整个 IP Header 的长度不是 4 字节的整数倍, 此时需要使用 Padding 字段来填充, Padding 字段的值必须设置为全 0
18.3 分类的 IPv4 地址
RFC 791 有一句经典的表述:
Internet Protocol
在 IP 协议中, IP 地址是关键的一个概念, 它用于唯一地标识一个实体, IPv4 使用的地址长度为 32 位, 为了人们方便阅读和表述, 通常将 32 位的 IP 地址使用形如 106.76.6.112 这样的点分十进制记法 (Dotted Decimal Notation), 目前 IP 地址的分配工作由 ICANN 来进行, IP 编址方法经过了多个阶段, 在早期, IP 地址被分为 A 类、B 类、C 类、D 类、E 类共 5 个分类, 此时 IP 地址在逻辑上是分层的, 一个 IP 地址由网络号 (net-id) 和主机号 (host-id) 构成, 即
网络号在整个 Internet 上是唯一的, 而主机号在其之前的网络号所限定的网络范围内是唯一的, 这样的网络号和主机号可以唯一确定一台主机, RFC 790 给出了分类 IP 地址的格式:
- 对于 A 类地址, 其最高位固定为 0 (该位可以看做是类别位), 网络号占 8 位, 主机号占 24 位

- 对于 B 类地址, 其最高的两位固定为 10, 网络号占 16 位, 主机号占 16 位

- 对于 C 类地址, 其最高三位固定为 110, 网络号占 24 位, 主机号占 8 位

-
而对于 D 类地址, 其最高四位固定为 1110, D 类地址是用于 IP Multicasting (IP 多播, 见 RFC 1112)
-
对于 E 类地址, 其最高四位固定为 1111, 仅保留用作实验用途
对于 A 类地址来说, 其主机号为 8 位, 类别位占 1 位, 这样共有 7 位是自由的, 但该 7 位全 0 代表本网络 (this network), 一般用于 ICMP 协议 [RFC 792], 而全 1 保留用作 Loop Back Test (如 127.0.0.1), 因此 A 类地址的网络号共有 个, A 类的地址的主机号有 24 位, 全 0 代表用作表示网络地址, 不用做具体的某个主机地址, 全 1 表示该网络上的所有主机, 也不用做具体的某个主机地址, 因此 A 类地址的一个网络号下可以分配的主机 IP 地址数为 , A 类地址一个网络下可分配的主机 IP 数非常多, 因而在设计时主要考虑分配给大型结构, 通过分析 A / B / C / D / E 类 IP 地址的划分方法可以看到, 该种分类方式存在很多问题, 比如不同类别的网络号所支持的主机数相差悬殊, Gap 很大, 这会使得 IP 地址空间利用率降低 (例如机构的主机数在 N 左右, 但 B 类地址不足以满足其需求, 但使用 A 类地址又会有大量富余, 但该机构只能申请 A 类地址, 从而造成地址空间的浪费), 另外, 只使用一个网络号将会使得路由表的表项数目变得庞大, 因为一个网络号下有大量的主机, 过大的路由表将会降低路由性能, 使得 IP Datagram 的交付效率变低等, 为了解决这些问题, RFC 950 提出了子网划分 (subnetting) 的概念
18.4 IPv4 子网划分与子网掩码
子网划分是在一个网络号下进一步将网络划分为若干个单元, 具体做法是从 IP 地址的主机号中选取 N 位作为子网号, 这样 IP 地址在逻辑上就变为了三层结构, 即
从网络外部来看, 网络号的位数没有发生任何变化, 因而其对外仍然表现为一个整体的网络, 但子网号的引入将会使得一个网络号下所能分配的主机 IP 数减少, 以 B 类地址为例, 进行子网划分后的 IP 地址结构如下所示:

当进行了子网划分以后, 路由选择算法需要做一定的修改, 在子网划分之前, 当 Datagram 到达网络号对应的网络之后, 根据主机号去确定目标主机 (目标网络维护了主机号与主机 MAC 地址的映射表), 但在子网划分之后, Datagram 在到达对应网络后需要首先找到目标主机所在的子网, 然后在该子网中再根据主机号确定目的主机, 子网的确定是通过子网掩码 (subnet mask) 来确定的, 假设网络号为 N 位, 子网号为 M 位, 则子网掩码的值就是 N + M 个连续的 1, 其后跟随 32 - (N + M) 个 0, 当子网掩码确定后, 只需将 IP 地址与子网掩码进行按位与, 就可以得到目标主机所在的子网, 再根据主机号即可将 Datagram 交付给目标主机 (子网中的网关维护了主机号与主机 MAC 地址的映射表)
为了与之前未使用子网划分时统一, 即便没有子网划分时也需要有子网掩码, 此时子网掩码使用的是默认子网掩码, 对于 A 类地址来说, 默认子网掩码就是 1111111100...., 此时仍然使用子网掩码与 IP 地址进行按位与仍然可以确定目标主机所在的网络
划分子网时, 如果网络号所占的位数是固定的, 那么每一个子网下所能容纳的最大主机数也都是相同的, 这样并不灵活, 因为在实际应用场景中, 在同一单位内部, 子机构的主机数目并不都是完全相等的, RFC 1009 指出在一个网络号下的子网号的长度可以不唯一, 进而不同子网使用的子网掩码也不相同, 具体细节读者可自行阅读 RFC 1009
18.5 IPv4 CIDR
RFC 1519 提出了 Classless Inter-Domain Routing (无分类域间路由选择), 简写为 CIDR, CIDR 主要是为了解决分类的 IPv4 地址各类别可容纳的主机数差异太大的问题, 该项缺点我们已在上面讨论过, 由于各个类别的网络号下所能容纳的主机数目差异很大, 因此不能很好地满足不同机构对不同主机数的要求, 申请高类别的 IP 造成大量的 IP 地址浪费, 而使用多个低类的 IP 又会增大路由表的表项数目, 因此在 1993 年, RFC 1519 提出了 CIDR 的编址方法, CIDR 取消了 IP 地址的类别, 而使用网络前缀 (prefix), 前缀的长度是可变的, 这就使得分配 IP 地址块时变得灵活了很多, 可以根据机构的需求为其分配相吻合数目的地址块, CIDR 的 IP 地址结构如下
使用 CIDR 之后, IP 地址可用形如 105.17.2.112/20 这样的记法来描述, 其中 20 代表网络前缀的长度, 而后 10 位对应的是主机号, 网络前缀的长度是可变的, 因此可以通过调整网络前缀的长度来分配不同大小的 IP 地址块, 使用 CIDR 后虽然没有子网划分的概念了, 但为了与仍在使用子网划分的网络统一, CIDR 仍然有掩码的概念, 同时 CIDR 地址块内部也仍然可以进行子网划分, 若不进行子网划分, 则 CIDR 掩码中前缀 1 的长度就是网络前缀的长度, 若 CIDR 内部进行了子网划分, 则 CIDR 掩码中前缀 1 的长度等于网络前缀的长度 + 子网号的长度
18.6 IPv4 路由 (Route)
IP 协议的核心在于路由, 路由算法的性能将决定 IP Datagram 交付的效率, 正如 RFC 791 所提出的: A name indicates what we seek. An address indicates where it is. A route indicates how to get there. IP 路由算法有很多, 如 RIP Route [RFC 2453], OSPF Route [RFC 2328] 等, 由于路由算法需要讨论的内容比较多, 我将在以后的博客中单独讨论 IP 路由算法的设计与工作原理
18.7 IPv4 to IPv6
IPv4 于上世纪八十年代初设计, 当时没有考虑到互联网终端的增长速度如此之快, IPv4 的地址早已分配完毕, 早在上世纪九十年代, IETF 就着手开始设计新版的 IP 协议, 即 IP Version 6 [RFC 2460](Deprecated), [RFC 8200], IPv6 将地址标识符拓展到 128 位, 在预见的未来, IPv6 几乎不需要考虑地址空间耗尽的问题, 但互联网协议往往具有巨大的惯性, 一个协议从提出到全面推广往往需要漫长的时间, 需要大量基础设施的升级, 即便目前, IPv6 的使用率仍然不高, 当然, 这主要也是由于 NAT (Network Address Translation, 网络地址转换) [RFC 2663] 协议使得设备可以使用内网 IP 地址而共用相同的公网 IP, 但 IPv6 仍是未来的趋势, 我将在下一篇博客中全面讨论 IPv6